

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 훈련일기
- AI스쿨7기
- KDT
- 멋사AI스쿨
- 부산하이스퀘어
- A/B테스트
- AI스쿨
- 통계학
- 머신러닝
- 혼동행렬
- 멋사7기
- growit
- 블로그챌린지
- 멋쟁이 사자처럼
- 블로그수익화기초
- 재현율
- 가설설정
- 회고
- 그로잇
- MINI프로젝트
- 멋사AI7기
- 회고록
- 빅데이터
- f1score
- 부산청년커뮤니티
- 멋사AI스쿨7기
- t-test
- http_method
- 멋쟁이사자처럼KDT
- 실험설계
- Today
- Total
언빌리버블티
[KDT] 공공데이터를 활용한 서울시 대중교통 이용현황 분석 - (2) Seaborn과 matplotlib을 활용한 시각화 본문
[KDT] 공공데이터를 활용한 서울시 대중교통 이용현황 분석 - (2) Seaborn과 matplotlib을 활용한 시각화
나는 정은 2022. 10. 27. 17:35멋쟁이 사자처럼 AI스쿨 7기
제 2회 미니 프로젝트 회고 - 2 (2022-10-11 ~ 2022-10-16)
서울시 공공데이터 분석 : Pandas를 활용한 서울 대중교통 이용현황 데이터 수집
공공데이터를 활용한 서울시 연간 대중교통 이용현황 분석
- T-money 교통카드 통계자료 (2017 ~ 2022 5년 간 자료) 수집
- 서울시 지하철호선별/역별 승하자 인원 정보 데이터 수집 (서울 열린데이터 광장)
- 서울시 지하철역 위치 정보 데이터 수집
- https://www.data.go.kr/data/15099316/fileData.do (서울교통공사_1_8호선 역사 좌표(위경도)정보)
- https://www.data.go.kr/data/15041335/fileData.do (국가철도공단_수도권9호선_역위치)
- https://ciy545.tistory.com/m/335 정제된 지하철역 위치 좌표 데이터 다운로드
- 서울시 월별 공공자전거 이용정보

0. 시각화 라이브러리 로드
import seaborn as sns
import matplotlib.pyplot as plt
import koreanize_matplotlib
import folium
1. 버스 정류장 연간 이용자수 변화 (2019 ~ 2022)
raws = [raw_2019, raw_2020, raw_2021, raw_2022]
raw = pd.concat(raws)
df = raw[['사용월', '연도', '월', '노선번호', '노선명', '버스정류장명', '승차승객수', '하차승객수']]a. 연도 & 월별 총 승차 승객 수 시각화
sns.catplot(data=df, x="월", y="승차승객수", hue="연도", kind="bar", ci=None, aspect=2, estimator=np.sum)
b. 연도 & 월별 하차 승객 수 시각화
sns.catplot(data=df, x="월", y="하차승객수", hue="연도", kind="bar", ci=None, aspect=2, estimator=np.sum)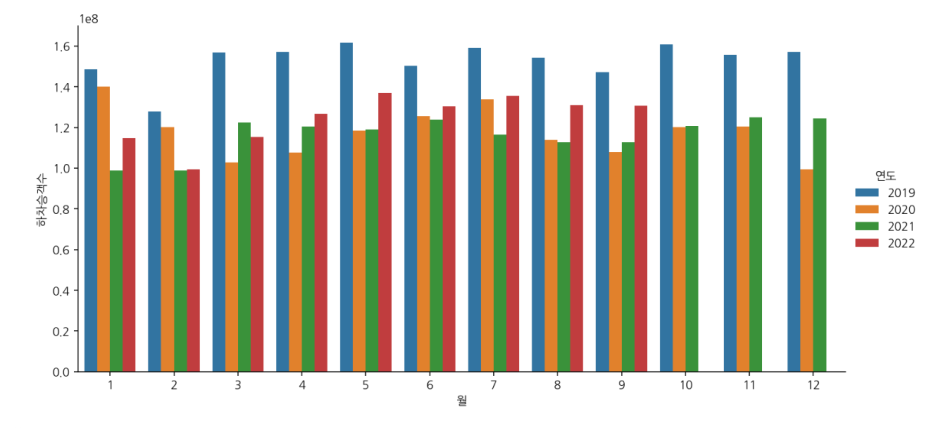
- 별다른 인사이트를 찾지 못했다.
- 1월~2월 , 6~7월에 이용자수가 잠깐 많아졌다가 다시 감소하였다
c. 버스정류장 top20
boxplot, violinplot
bus_stop = rank_bus_stop(ratio_bus_stop(bus_stop))
bus_stop_top20 = bus_stop.sort_values(by='종합순위').head(20).reset_index()
plt.figure(figsize=(20,20))
plt.subplot(221)
bus_stop_top20[['승차승객수', '하차승객수']].boxplot()
plt.subplot(222)
sns.violinplot(data=bus_stop_top20[['승차승객수', '하차승객수']])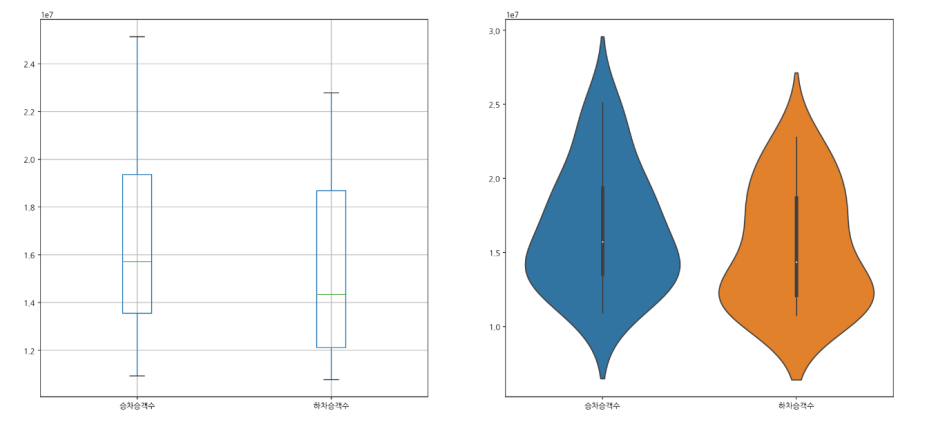
d. 승차인원 수 top20 버스정류소
plt.figure(figsize=(50,15))
plt.title('버스 정류소별 승차 인원',fontsize=30)
sns.barplot(data=bus_stop_top20, x='버스정류장명', y='승차승객수')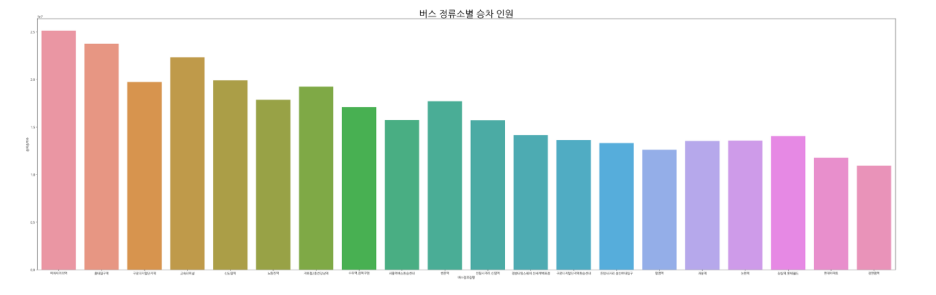
e. 하차인원 수 top20 버스정류소
plt.figure(figsize=(50,15))
plt.title('버스 정류소별 하차 인원',fontsize=30)
sns.barplot(data=bus_stop_top20, x='버스정류장명', y='하차승객수')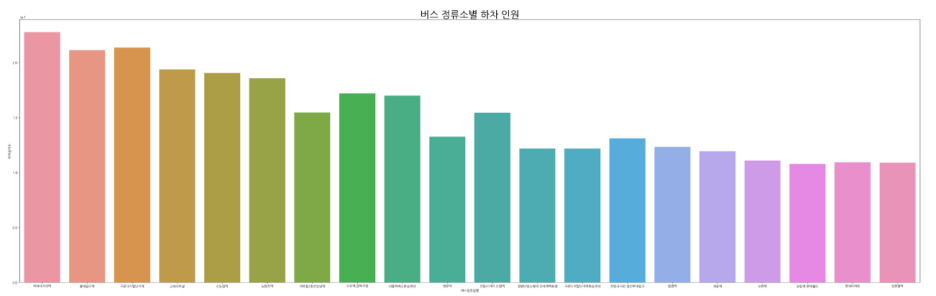
2. 지옥철 TOP 20 천국철 TOP 20
a. 지하철 연간 이용자 수 변화
df.groupby(['연도월'])[['승차총승객수','하차총승객수']].sum().plot(figsize = (10,3), rot=70)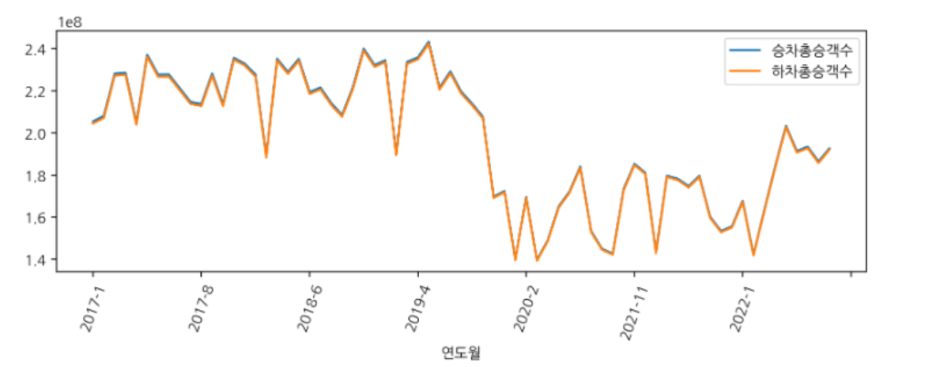
- 승하차 승객 수 차이는 없었고, 코로나 사태가 시작된 2020년 초부터 총 이용객 수가 감소
b. 요일별 지하철역 유동인구 히트맵
# 상위 20
df_pivot = df_top20.pivot_table(index = ['노선_역명'], columns = '요일', values = '총이용자수',aggfunc = 'sum')
df_pivot = df_pivot[['월','화','수','목','금','토','일']]
df_pivot = df_pivot / 10000 # 만명단위로 수정
# 그래프 그리기
fig, ax = plt.subplots( figsize=(6,len(df_pivot)/3 ) )
# 그래프 사이즈를 조정하여, 역 수가 많은 경우는 세로를 길게 표현.
plt.title(f"각 지하철역의 요일별 승객수 (단위 : 만명)", fontsize = 15) # for title
sns.heatmap(df_pivot, cmap = "RdBu_r", annot = True, fmt = '.0f')
- 2호선 라인에 위치한 역에 인구가 밀집하는 것을 알 수 있었다.
#하위 20
df_pivot = df_bottom20.pivot_table(index = ['노선_역명'], columns = '요일', values = '총이용자수',aggfunc = 'sum')
df_pivot = df_pivot[['월','화','수','목','금','토','일']]
# 그래프 그리기
fig, ax = plt.subplots( figsize=(6,len(df_pivot)/3 ) )
# 그래프 사이즈를 조정하여, 역 수가 많은 경우는 세로를 길게 표현.
plt.title(f"각 지하철역의 요일별 승객수 (단위 : 명)", fontsize = 15) # for title
sns.heatmap(df_pivot, cmap = "RdBu_r", annot = True, fmt = '.0f')
- 승객 수가 아주 적게 이용하는 지하철역도 알아볼 수 있었다.
3. 각 연도별 지하철 이용객 수 변화
a. 연간 상위 20개역 총 이용객 수
plt.figure(figsize=(27,15))
sns.barplot(data=df_top20,x='연도',y = '총이용자수',ci=False)
plt.xticks(rotation=30,fontsize=18)
plt.yticks(fontsize=18)
plt.title('연간 상위 20개역 지하철 이용자수 변화',fontsize = 20)
b. 연간 하위 20개역 총 이용객 수
plt.figure(figsize=(27,15))
sns.barplot(data=df_bottom20,x='연도',y = '총이용자수',ci=False)
plt.xticks(rotation=30,fontsize=18)
plt.yticks(fontsize=18)
plt.title('연간 하위 20개역 지하철 이용자수 변화',fontsize = 20)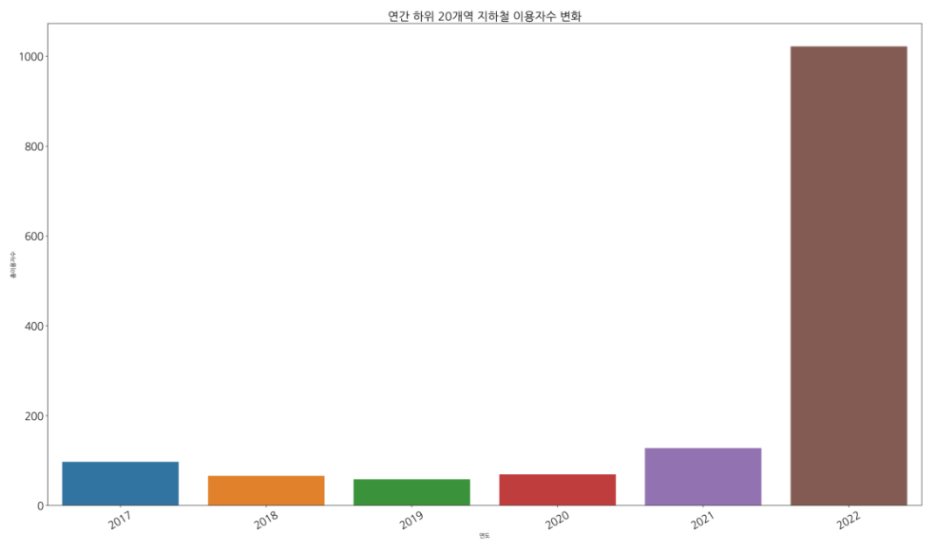
4. 서울시 공공자전거 따릉이 이용자수 증가
a. 지하철 총 이용객수의 감소 (2019 ~ 2022)
plt.figure(figsize=(10,8))
plt.xticks(rotation=70)
plt.title('총 이용자 수',fontsize=15)
sns.lineplot(data=df, x='월', y='총이용자수',hue='연도',ci=None,estimator=sum)
- 지하철 총 이용객 수가 감소하였다.
b. 공공자전거 이용객 수의 증가 (2019 ~ 2022)
# 공공자전거 연도-월 별 이용자수 변화
plt.figure(figsize=(10,8))
plt.xticks(rotation=70)
plt.title('서울시 공공자전거 이용자 수 변화',fontsize=15)
sns.lineplot(data=df_bike, x='월', y='대여건수',hue='연도',ci=None,estimator=sum)
# 누적 이용자수
df_all.plot(secondary_y='누적대여건수', figsize=(15,3))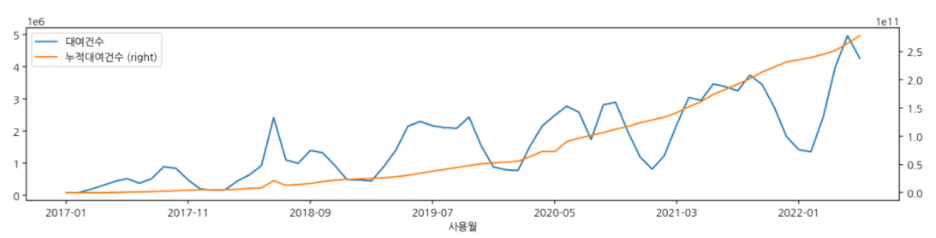
- 지하철 이용자수는 감소한 반면에 공공자전거의 대여횟수는 크게 증가하였다.
c. 연간 공공자전거 이용자수 변화 (2017~2022)
plt.figure(figsize=(10,8))
plt.xticks(rotation=70)
plt.title('서울시 공공자전거 이용자 수 변화',fontsize=15)
sns.lineplot(data=df_bike, x='월', y='대여건수',hue='연도',ci=None,estimator=sum)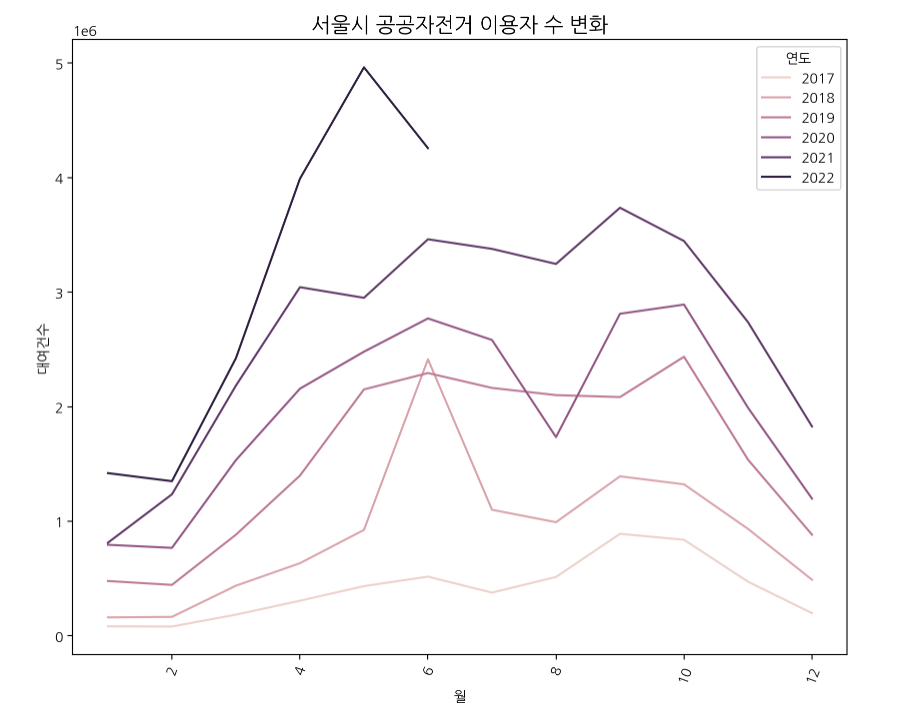
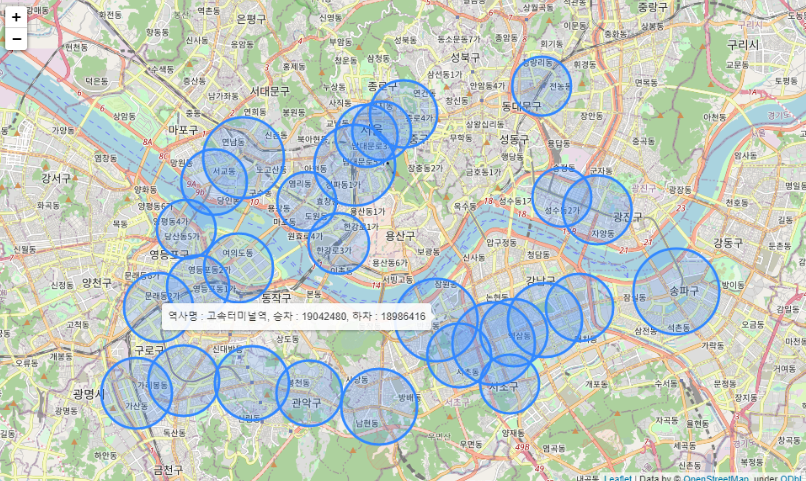
5. 가장 많이 이용하는 지하철역의 위치 알아보기 - folium
- 역별 유동인구와 승하차 인원 시각화를 위해 전처리 후 merge
# 역사별 승하차인원에 위경도 데이터 merge
on_off = pd.pivot_table(df, index="지하철역", columns="승하차", values="승하차인원", aggfunc="sum")
on_off = on_off.merge(raw, on="지하철역")
on_offa. 전체 지하철역 위치 시각화
import folium
center = [37.563, 126.986]
zoom = 12
m = folium.Map(center, zoom_start=zoom)
for i in on_off.index:
m_name = on_off.loc[i, "지하철역"]
m_long = on_off.loc[i, "경도"]
m_lat = on_off.loc[i, "위도"]
m_on = on_off.loc[i, "승차"]
m_off = on_off.loc[i, "하차"]
radius = np.sqrt(np.sqrt(m_on + m_off)) - 30
tooltip = f"역사명 : {m_name}, 승차 : {m_on}, 하차 : {m_off}"
folium.CircleMarker([m_lat, m_long],
radius=radius,
fill=True,
tooltip=tooltip).add_to(m)
m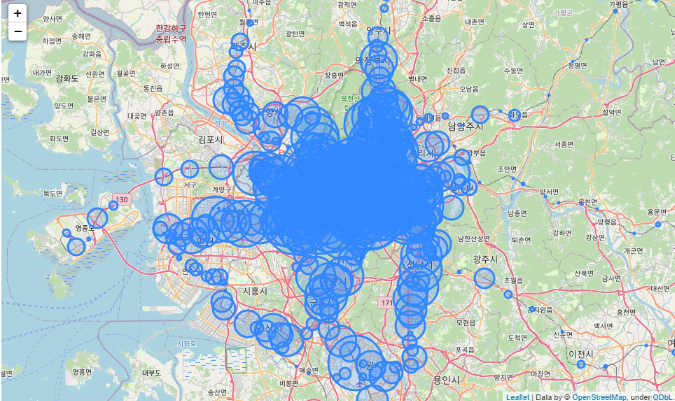
b. 유동인구수 합계 상위 30개 지하철역만 추출하여 시각화
# 승하차 인원을 더한 유동인구 칼럼 생성
on_off["유동인구"] = on_off["승차"] + on_off["하차"]
on_off
# 유동인구 상위 30개역만 추출
top_30 = on_off.iloc[on_off["유동인구"].nlargest(30).index].reset_index(drop=True)
top_30center = [37.563, 126.986]
zoom = 12
m = folium.Map(center, zoom_start=zoom)
for i in top_30.index:
m_name = top_30.loc[i, "지하철역"]
m_long = top_30.loc[i, "경도"]
m_lat = top_30.loc[i, "위도"]
m_on = top_30.loc[i, "승차"]
m_off = top_30.loc[i, "하차"]
radius = np.sqrt(np.sqrt(m_on + m_off)) - 30
tooltip = f"역사명 : {m_name}, 승차 : {m_on}, 하차 : {m_off}"
folium.CircleMarker([m_lat, m_long],
radius=radius,
fill=True,
tooltip=tooltip).add_to(m)
m
6. 결론
- 2019년 이후 지하철 이용자 수 급격히 감소
- 코로나의 영향을 크게 받았을 것이라 추측해볼 수 있었다.
- 대중교통 수요가 감소함과 동시에 공공자전거 같은 교통수단의 수요가 증가세를 보이고 있었다.
- 따릉이 외에도 전동킥보드, 오토바이, 택시와 같은 개인 이동수단 이용률이 좀 더 증가했을 것 같다는 추측
- 그래도 평일 2호선의 유동인구가 매우 많은 것으로 판단된다.
- 조금 더 디벨롭해서 주변 상권 분석이나 지하철역 인구밀집도에 따른 사고*범죄 현황에 대한 데이터도 함께 알아보면 좋을 것 같다.
- 코로나 이후 대중교통 관련 범죄율이 줄어들었을지 궁금증이 생겼다.
- 개인 이동수단의 사고발생률은 어느 정도 변화하였을지 궁금증이 생겼다.
🎃두 번째 미니 프로젝트 회고
2번째 미니프로젝트가 무사히 마무리되었다!
월요일이 휴일이라 화수목 강의듣고 , 금요일 특강듣고 저녁에 짬내서 수집한 데이터로 주말 동안 시각화하고
결과보고서까지 작성했어야 했는데 복습, 과제, 프로젝트가 겹치면서 시간관리가 전혀 안되는걸 몸소 느꼈다
정신적, 체력적으로 많이 힘들었던 4일이었다. 🥲🥲🥲
주제를 명확하게 정하지 않고데이터만 무지성으로 끌어오고 분석할려고 하다보니 어려움을 많이 겪었다.
와중에 카카오 서버 날아가는 바람에 티스토리가 먹통이 되고, 시각화할 때 무슨 툴을 사용해야할 지
어떻게 시각화하고 어떤 정보를 담아야 하는지 방향을 잃어버리는 이슈가 발생했다 😭
무엇을 분석할 것인가에 대한 고민을 깊게 하지 않고 시작해서 데이터를 수집을 해도 어떻게 전처리하면 좋을지 도무지 아이디어가 떠오르지 않았었다. 또한 join으로 데이터를 merge하는 과정이 복잡하고 어렵게 느껴졌다.
시간대 별 지하철 이용 현황을 시각화하려고 했으나 월-일-시간대 가 함께 있는 데이터셋을 구하기가 어려웠다.
데이터를 다 긁어 모아 concat을 해보려 했지만 시간이 부족해서 다 시도해보지 못한게 아쉽다.
csv 파일의 인코딩 방식이 uft-8 , cp949 각각 다르게 저장되어있어서 초반에 한꺼번에 불러오려니 에러가 계속 발생했다. 앞전에 공부했던 예외처리 코드를 활용하여 해당 이슈를 해결할 수 있었고, 이 부분을 응용하여 엑셀인 경우 , csv인 경우를 구분하여 데이터를 한꺼번에 불러오는 코드를 작성해볼 수 있었다.
GitHub의 필요성을 느꼈다 .. 🥲
'2022 > MINI' 카테고리의 다른 글
| [KDT] Students Academic Performance Prediction (ML Classification, kaggle) (0) | 2022.11.11 |
|---|---|
| [KDT] 내 거친 성적과 불안한 공교육💦 : 대한민국 사교육 환경 변화와 원인 분석 (4) | 2022.10.27 |
| [KDT] 공공데이터를 활용한 서울시 대중교통 이용현황 분석 - (1) 데이터 수집 및 전처리 (0) | 2022.10.27 |
| [KDT] YouTube API를 활용하여 수집한 데이터 분석하기 (2) KoNLPy 단어 형태소 추출 & WordCloud 시각화 (0) | 2022.10.05 |
| [KDT] YouTube API를 활용하여 영상 데이터 리스트업하기 (1) YouTube API 호출하기 (0) | 2022.10.04 |



