
언빌리버블티
[KDT] 공공데이터를 활용한 서울시 대중교통 이용현황 분석 - (1) 데이터 수집 및 전처리 본문
멋쟁이 사자처럼 AI스쿨 7기
제 2회 미니 프로젝트 회고 - 1 (2022-10-11 ~ 2022-10-16)
서울시 공공데이터 분석 : Pandas를 활용한 서울 대중교통 이용현황 데이터 수집
공공데이터를 활용한 서울시 연간 대중교통 이용현황 분석
분석할 교통수단 선정
- 주어진 시간상의 이유로 가장 많이 이용되고 있는 도시 내 이동수단인 지하철과 시내버스 데이터를 활용하였다.
- 개인이동수단의 이용률과 함께 비교해보고자 서울시 공공자건거 "따릉이" 이용현황에 대한 데이터도 함께 수집하였다.
활용 데이터
- T-money 교통카드 통계자료 (2017 ~ 2022 5년 간 자료) 수집
- 서울시 지하철호선별/역별 승하자 인원 정보 데이터 수집 (서울 열린데이터 광장)
- 서울시 지하철역 위치 정보 데이터 수집
- https://www.data.go.kr/data/15099316/fileData.do (서울교통공사_1_8호선 역사 좌표(위경도)정보)
- https://www.data.go.kr/data/15041335/fileData.do (국가철도공단_수도권9호선_역위치)
- https://ciy545.tistory.com/m/335 정제된 지하철역 위치 좌표 데이터 다운로드
- 서울시 월별 공공자전거 이용정보
0. 라이브러리 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import koreanize_matplotlib
import datetime as dt
from dateutil.parser import parse
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'
pd.set_option('display.float_format', '{:.1f}'.format)
file_names = sorted(glob('dataset/2022*.xls'))1. 데이터 수집
a. 티머니 시간대 지하철 승하차수 데이터 수집
# 지하철 이용자 수 데이터
def concat_subway(file_names):
raw = pd.DataFrame()
for file_name in file_names:
df = pd.read_excel(file_name, sheet_name=sheets[3])
del df['작업일시']
col_name = [*df.columns[:4]]
for i in range(4,len(df.columns)-1,2):
if 'Unnamed' in df.columns[i+1]:
time = int(df.columns[i][:2])%24 if df.columns[i][:2] != '00' else 24
col_name.append(f'{time}시_승차')
col_name.append(f'{time}시_하차')
col_name = col_name[:4] + col_name[-6:] + col_name[4:-6]
df = df.set_axis(col_name, axis = 'columns').drop(index = 0)
raw = pd.concat([raw, df], ignore_index=True)
print(raw.shape)
return raw
raw = concat_subway(file_names) - pd.read_excel(file_name, sheet_name = sheets[number])
- 티머니 교통카드 이용현황 데이터 엑셀파일의 3번째 시트를 불러왔다.
- 2017년부터 2022년까지의 자료를 하나의 데이터프레임으로 concat한 뒤 전처리하였다.
sheets = ['버스정류장별 이용현황', '지하철 노션별 역별 이용현황', '지하철 유무임별 이용현황', '지하철 시간대별 이용현황']
df_columns = ['사용월', '노선ID', '노선번호', '노선명', '버스정류장ID', '버스정류장명', '승차승객수', '하차승객수','작업일시']Index(['사용월', '호선명', '역ID', '지하철역', '04:00:00~04:59:59', 'Unnamed: 5',
'05:00:00~05:59:59', 'Unnamed: 7', '06:00:00~06:59:59', 'Unnamed: 9',
'07:00:00~07:59:59', 'Unnamed: 11', '08:00:00~08:59:59', 'Unnamed: 13',
'09:00:00~09:59:59', 'Unnamed: 15', '10:00:00~10:59:59', 'Unnamed: 17',
'11:00:00~11:59:59', 'Unnamed: 19', '12:00:00~12:59:59', 'Unnamed: 21',
'13:00:00~13:59:59', 'Unnamed: 23', '14:00:00~14:59:59', 'Unnamed: 25',
'15:00:00~15:59:59', 'Unnamed: 27', '16:00:00~16:59:59', 'Unnamed: 29',
'17:00:00~17:59:59', 'Unnamed: 31', '18:00:00~18:59:59', 'Unnamed: 33',
'19:00:00~19:59:59', 'Unnamed: 35', '20:00:00~20:59:59', 'Unnamed: 37',
'21:00:00~21:59:59', 'Unnamed: 39', '22:00:00~22:59:59', 'Unnamed: 41',
'23:00:00~23:59:59', 'Unnamed: 43', '00:00:00~00:59:59', 'Unnamed: 45',
'01:00:00~01:59:59', 'Unnamed: 47', '02:00:00~02:59:59', 'Unnamed: 49',
'03:00:00~03:59:59', 'Unnamed: 51'],
dtype='object')- Unnamed 컬럼을 제거하고 시간대별 승하차 컬럼을 새로 생성
사용월, 호선명, 역ID, 지하철역, 1시_승차, 1시_하차, 2시_승차, 2시_하차, 3시_승차, 3시_하차,
4시_승차, 4시_하차, 5시_승차, 5시_하차, 6시_승차, 6시_하차, 7시_승차, 7시_하차, 8시_승차,
8시_하차, 9시_승차, 9시_하차, 10시_승차, 10시_하차, 11시_승차, 11시_하차, 12시_승차, 12시_하차,
13시_승차, 13시_하차, 14시_승차, 14시_하차, 15시_승차, 15시_하차, 16시_승차, 16시_하차,
17시_승차, 17시_하차, 18시_승차, 18시_하차, 19시_승차, 19시_하차, 20시_승차, 20시_하차,
21시_승차, 21시_하차, 22시_승차, 22시_하차, 23시_승차, 23시_하차, 24시_승차, 24시_하차del df['역ID']
del df['승하차시간']
df['시간'] = df['시간'].str.replace('시','')
df['승하차인원'] = df['승하차인원'].str.replace(',','').map(lambda x : int(x))
df['사용월'] = pd.to_datetime(df['사용월']).dt.strftime('%Y-%m')
df['호선명'] = df['호선명'].str.replace('9호선2~3단계','9호선')- 각 컬럼 별 데이터 전처리 & melt() 적용

b. 티머니 시간대 버스 승하차수 데이터 수집
file_names = sorted(glob('data/tmoney/20*.xls'))
sheets = ['버스정류장별 이용현황', '지하철 노션별 역별 이용현황', '지하철 유무임별 이용현황', '지하철 시간대별 이용현황']
df_columns = ['사용월', '노선ID', '노선번호', '노선명', '버스정류장ID', '버스정류장명', '승차승객수', '하차승객수','작업일시']
raw = pd.DataFrame(columns=df_columns)
for file_name in file_names:
df = pd.read_excel(file_name, sheet_name=sheets[0])
raw = pd.concat([raw, df], ignore_index=True)
-
df = pd.read_excel("엑셀 파일 경로", sheet_name = "불러올 시트 이름")

(358608, 8)df_tmoney['노선ID'] = df_tmoney['노선ID'].astype(str)
df_tmoney['버스정류장ID'] = df_tmoney['버스정류장ID'].astype(str)
df_tmoney['승차승객수'] = df_tmoney['승차승객수'].map(lambda x : int(x.replace(',','')))
df_tmoney['하차승객수'] = df_tmoney['하차승객수'].map(lambda x : int(x.replace(',','')))
del df_tmoney['작업일시']- 노선 아이디 , 버스정류장 아이디 object형으로 수정
- 승하차 승객 수 데이터 자료형 int로 수정
- 작업일시 컬럼 제거
c. 지하철 역사 위치 데이터 수집 및 concat
# 티머니 시간대별 승하차 데이터
tmoney = pd.read_csv("2022_tmoney_subway.csv", low_memory=False)
tmoney.shape
# 지하철 위경도 데이터
raw = pd.read_excel("지하철_위경도.xlsx")
raw.shape
# 도시명이 서울에 속하는 것만 가져옴
raw = raw[raw["city_name"] == "서울"]
raw.shape(264576, 8)
(1058, 13)# 서울시 지하철역에 해당하는 좌표 추출
raw = raw[raw["city_name"] == "서울"]
raw = raw[["displayName", "point_x", "point_y"]]
raw.columns = ["지하철역", "경도", "위도"]

raw = raw.groupby("지하철역", as_index=False).mean()
raw- 환승역 중복 데이터 처리 : 중복된 지하철역을 처리하기 위해 위경도의 평균 값을 사용하여 groupbby
def preprocess_subway_name(data, col):
data[col] = data[col].replace('\([^)]*\)',"",regex=True)
data[col] = data[col].str.replace(" ", "")
data[col] = data[col].str.rstrip("역")
data[col]+="역"
preprocess_subway_name(tmoney, "지하철역")
preprocess_subway_name(raw, "지하철역")- replace() : T-money 전처리 데이터와 merge하기 위해 지하철 역사명 형식 통일 (정규표현식 사용)

# 데이터 merge
df = tmoney.merge(raw, on="지하철역")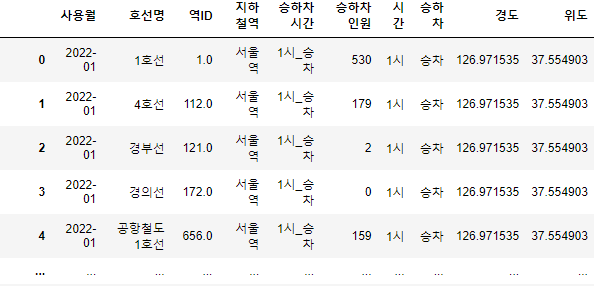
- 이렇게 데이터가 알맞게 들어간 것을 확인할 수 있었다 !
d. 서울시 공공자전거 따릉이 월별 이용 정보 수집
- 저장된 데이터의 칼럼명 지정 형식이 3가지 종류로 각각 다르게 지정되어있어서 따로 처리한 뒤 concat해주었다.
2017년 1월 ~ 2018년 11월 데이터 전처리
# 사용월 '201701' -> 201701 의 형태로 변경
def mapping(x):
x = str(x).replace("'",'')
return x[0:4] +'-' + x[4:]
# 각 칼럼 내 '' 삭제
def remove_dot(x):
return str(x).replace("'",'')
df['대여소명'] = df['대여소명'].apply(remove_dot)
return df
for file in file_names:
try:
raw = pd.read_csv(file,encoding='utf-8',index_col=False)
print(f'{file} 로드 완료 , encoding = "utf-8"')
except:
raw = pd.read_csv(file,encoding='cp949',index_col=False)
print(f'{file} 로드 완료, encoding = "cp949"')- 인코딩 방식에 따른 csv데이터 read 방법 예외처리
2018년 12월 ~ 2021년 12월 데이터 전처리
path_2 = f'dataset/seoul_bike/format_2/서울시*'
file_names_2 = sorted(glob(path_2))
# excel도 섞여있음
['dataset/seoul_bike/format_2\\서울시 공공자전거 201812_201905.xlsx',
'dataset/seoul_bike/format_2\\서울시 공공자전거 201906_201911.xlsx',
'dataset/seoul_bike/format_2\\서울시 공공자전거 201912_202005.xlsx',
'dataset/seoul_bike/format_2\\서울시 공공자전거 202006.csv',
'dataset/seoul_bike/format_2\\서울시 공공자전거 202007_202101.csv',
'dataset/seoul_bike/format_2\\서울시 공공자전거 202102_202106.csv',
'dataset/seoul_bike/format_2\\서울시 공공자전거 202107_202112.csv'] for file in file_names:
# 확장자가 xlsx인 경우와 csv 인 경우를 다르게 처리
try:
df.append(pd.read_excel(file, sheet_name='대여'))
except:
df.append(pd.read_csv(file,encoding='cp949',index_col=False))
df = pd.concat(df, ignore_index = True)- excel 파일과 csv 파일이 섞여 있을 경우의 예외처리
2022년 1월 ~ 2021년 6월 데이터 전처리
path_3 = f'dataset/seoul_bike/format_3/대여소*'
file_names_3 = sorted(glob(path_3))def mapping_3(x):
x = str(x)
return x[0:4]+'-'+x[4:]
def concat_format_3(file_names):
df = []
ym = [str(i) for i in range(202201,202207)]
columns = ['구분','팀명','대여소명','대여건수','사용월']
for year_month ,file in zip(ym, file_names):
try:
raw = pd.read_csv(file,encoding='utf-8',index_col=False)
print(f'{file} 로드 완료 , encoding = "utf-8"')
except:
raw = pd.read_csv(file,encoding='cp949',index_col=False)
print(f'{file} 로드 완료, encoding = "cp949"')
raw['사용월'] = year_month
df.append(raw)
df = pd.concat(df, ignore_index = True)
df = df.drop(columns = ['구분','팀명'])
df = df[['사용월','대여소명','대여건수']].set_axis(['사용월','대여소명','대여건수'], axis = 'columns')
df['사용월'] = df['사용월'].apply(mapping_3)
return df- 사용월에 대한 컬럼이 누락되어있어 따로 추가해준 뒤 concat
모든 연도별 csv 파일 병합
path = f'dataset/bike_year/format*'
file_names= sorted(glob(path))
df = []
for file in file_names:
df.append(pd.read_csv(file , index_col = 0))
df = pd.concat(df, ignore_index=True)
df.to_csv('dataset/bike_sharing_concat.csv')path = f'dataset/bike_year/format*'
file_names= sorted(glob(path))
>
['dataset/bike_year\\format_1.csv',
'dataset/bike_year\\format_2.csv',
'dataset/bike_year\\format_3.csv']
df = []
for file in file_names:
df.append(pd.read_csv(file , index_col = 0))
df = pd.concat(df, ignore_index=True)
df.to_csv('dataset/bike_sharing_concat.csv')- 모든 csv파일 전체 병합
- ignore_index = True , 인덱스는 저장하지 않는다.
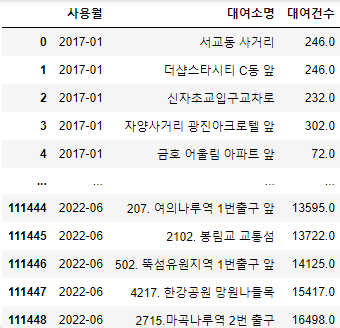
시각화를 위한 데이터 전처리 및 파생변수 생성
df_bike.info()
df_bike = df_bike.dropna()
# 날짜 파생 변수 생성
df_bike['사용월'] = pd.to_datetime(df_bike['사용월']).dt.strftime('%Y-%m')
df_bike['연도'] = df_bike['사용월'].map(lambda x : int(x[:4]))
df_bike['월'] = df_bike['사용월'].map(lambda x : int(x[5:]))
# 누적합
df_bike['누적대여건수'] = df_bike['대여건수'].cumsum()
df_all = df_bike.groupby('사용월')[['대여건수','누적대여건수']].sum()
df_all- dropna() : Null 값이 포함된 행 제거
- 날짜 및 누적 대여건수 파생변수 생성
'Data Science > KDT' 카테고리의 다른 글
| [KDT] 내 거친 성적과 불안한 공교육💦 : 대한민국 사교육 환경 변화와 원인 분석 (4) | 2022.10.27 |
|---|---|
| [KDT] 공공데이터를 활용한 서울시 대중교통 이용현황 분석 - (2) Seaborn과 matplotlib을 활용한 시각화 (0) | 2022.10.27 |
| [KDT] YouTube API를 활용하여 수집한 데이터 분석하기 (2) KoNLPy 단어 형태소 추출 & WordCloud 시각화 (0) | 2022.10.05 |
| [KDT] YouTube API를 활용하여 영상 데이터 리스트업하기 (1) YouTube API 호출하기 (0) | 2022.10.04 |
| [KDT] Python 웹 스크래핑으로 네이버 금융 개별종목 데이터 수집 (0) | 2022.09.29 |
'Data Science/KDT' Related Articles
more




Comments