
언빌리버블티
[KDT] 서울시 코로나19 데이터 발생동향 EDA - 2 본문
멋쟁이 사자처럼 5주차
2022.10.12
서울시에서 공개한 코로나19 발생동향 분석 - EDA (2)
라이브러리 로드 ~ 파생 변수 만들기
4. 전체 확진일에 대한 기간 데이터 생성
a. 첫 확진일과 마지막 확진일 구하기
last_day = df['확진일'].max()
first_day = df['확진일'].min()(Timestamp('2020-01-24 00:00:00'), Timestamp('2021-12-26 00:00:00'))b. data_range를 이용하여 전체 기간 데이터 생성
all_day = pd.date_range(start=first_day, end=last_day)
all_day- pd.date_range(start =, end =) : 시작하는 날짜부터 종료날짜까지 매일의 날짜를 생성한다.
df_allday = all_day.to_frame()
df_allday
- to_frame() : 데이터 프레임으로 다시 변환한다.
c. 확진자 수 컬럼을 합쳐주고 결측치 제거
df_allday['확진수'] = day_count
del df_allday[0] # 필요 없는 0 컬럼 삭제
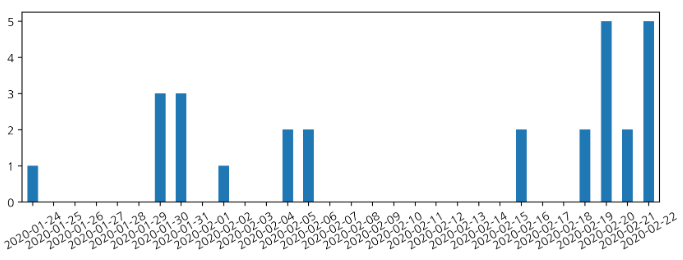
df_allday = df_allday.fillna(0)d. 확진자 발생 초반 30일의 데이터 시각화하기
# 날짜만 표시
df_allday.index = df_allday.index.astype(str)
df_allday['확진수'][:30].plot(kind='bar', figsize=(10,3), rot=30)- index.astype(str) : index의 형식을 문자열로 변환하여 x Label로 사용
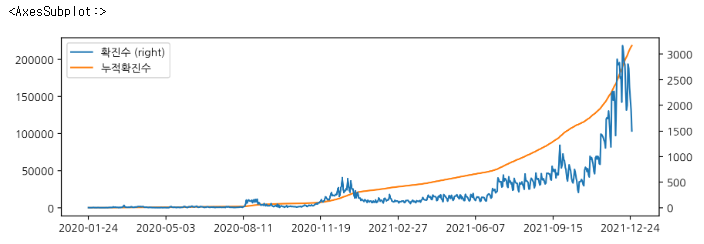
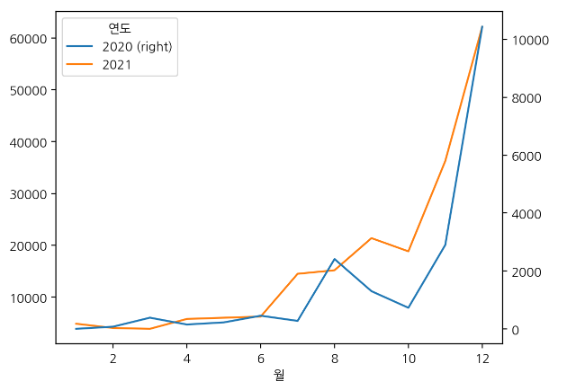
e. 누적 확진자 수 시각화
df_allday['누적확진수'] = df_allday['확진수'].cumsum()
df_allday.plot(secondary_y='확진수', figsize=(10,3))
5. 거주지 데이터 전처리
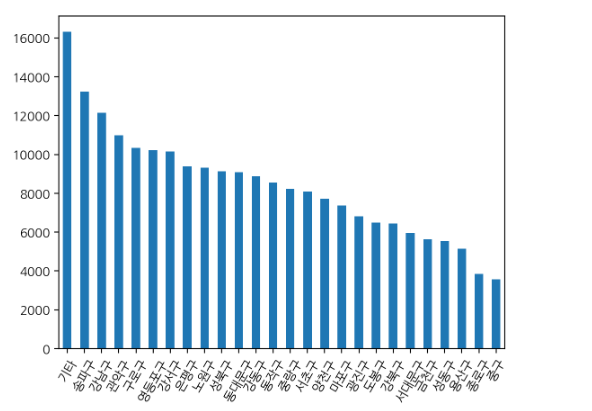
df['거주구'] = df['거주지'].str.strip()
df['거주구'] = df['거주구'].str.replace('타시도','기타')
gu_count = df['거주구'].value_counts()
gu_count.plot(kind='bar', rot=60)- strip() : 공백을 제거해줌으로써 같은 데이터가 따로 집계되지 않도록 처리
- replace() : 타시도로 입력되어있는 관측치를 기타로 변경 후 집계
6. 두 개 변수에 대해 빈도수와 비율 계산
- pd.crosstab 활용
a. 연도와 퇴원현황
cross = pd.crosstab(df['연도'],df['퇴원현황'])
cross['사망률'] = round(cross['사망'] / (cross["사망"] + cross["퇴원"]) * 100, 2)
cross['퇴원율'] = round(100 - cross['사망률'], 2)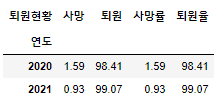
b. 연도와 월
year_month = pd.crosstab(df["연도"], df["월"])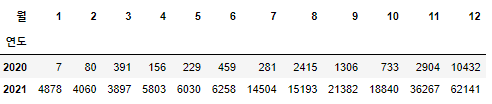
c. 연도와 요일
year_weekday = pd.crosstab(df["연도"], df["요일명"])
weekday_list = [year_weekday[weekday] for weekday in list("월화수목금토일")]
year_weekday = pd.concat(weekday_list, axis = 1)- 각 요일 칼럼이 sorting되지 않은 상태로 출력되므로 리스트 컴프리헨션을 통해 columns 순서를 재정비한다.
- concat() : 순서를 바꾼 데이터프레임들을 합친다.
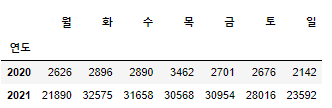
year_weekday.T.plot(kind='bar',secondary_y=2020, rot=360)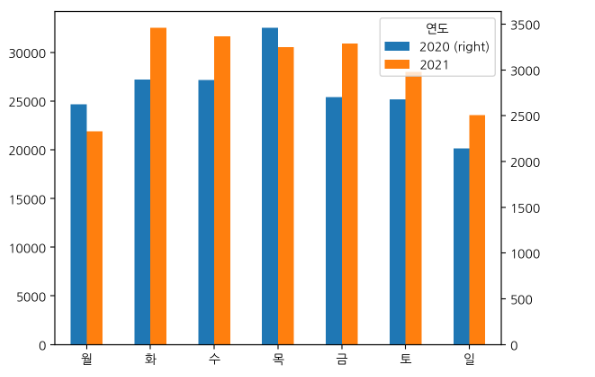
d. 거주구와 연도-월
pd.crosstab(df['거주구'],df['연도']).T.style.background_gradient()
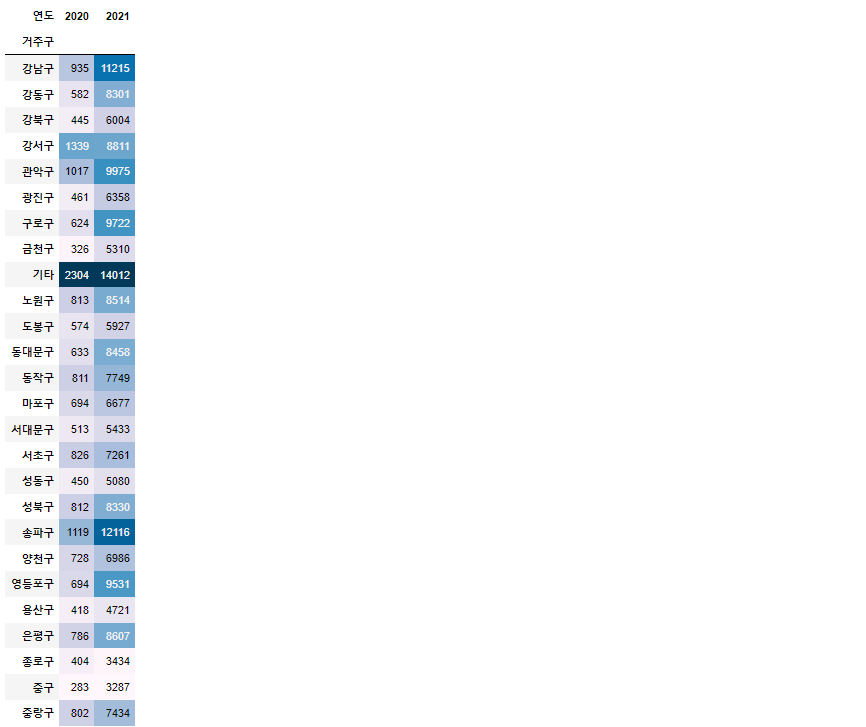
7. 거주구별 해외유입 확진자 비율 계산
a. 확진자 해외유입 여부 구분
df['해외유입'] = np.where(df['접촉력'] == '해외유입', 1 , 0)
gu_over_count = pd.crosstab(df["거주구"], df["해외유입"])
gu_over_count["비율"] = gu_over_count[1] / (gu_over_count[0] + gu_over_count[1]) * 100- np.where() : 조건이 참인 값 , 거짓인 값을 array형식으로 반환하여 새로운 파생 변수 생성
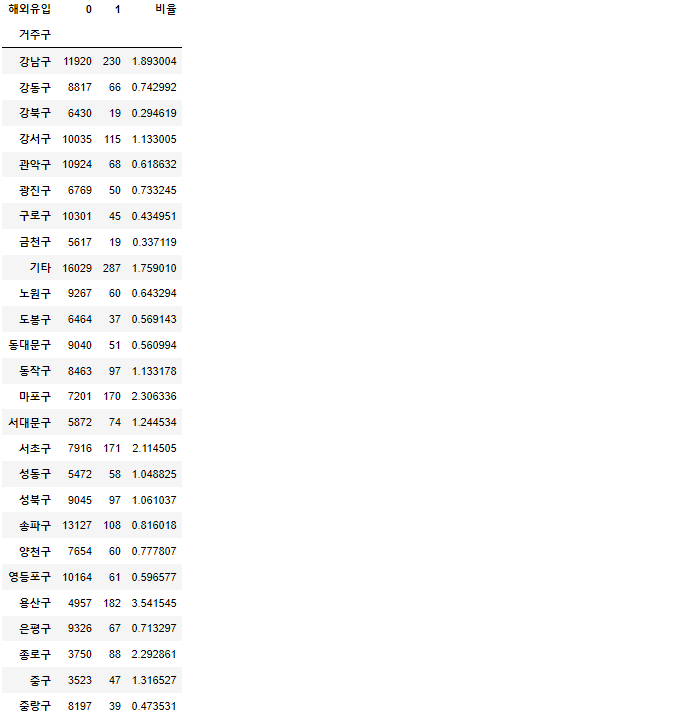
gu_over_count.iloc[:,:2].plot(kind='bar',stacked = True,rot=70)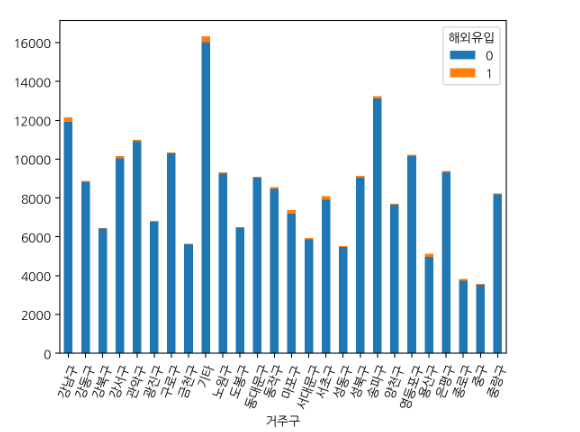
- 송파구, 강남구, 관악구 , 기타 지역 확진자가 다른 지역보다 평균 확진자 수가 많았다는 것을 알 수 있었다!
Reference
멋쟁이 사자처럼 ai스쿨 "오늘코드" 박조은 강사님께 제공받은
서울시 코로나19 확진자 현황(2020~2021) 데이터를 바탕으로 탐색적 데이터 분석을 수행하였음
'Data Science > Side' 카테고리의 다른 글
| [KDT] 서울시 코로나19 데이터 발생동향 EDA - 1 (0) | 2022.10.12 |
|---|---|
| [KDT] 서울시 다산콜센터(☎120)의 질문 답변 내용 수집 - Python Web Crawling (0) | 2022.10.06 |
| [KDT] 서울시 다산콜센터(☎120)의 주요 민원(자주 묻는 질문) 수집 - Python Web Crawling (0) | 2022.10.05 |
'Data Science/Side' Related Articles
more



Comments