
언빌리버블티
[KDT] 서울시 다산콜센터(☎120)의 주요 민원(자주 묻는 질문) 수집 - Python Web Crawling 본문
Data Science/Side
[KDT] 서울시 다산콜센터(☎120)의 주요 민원(자주 묻는 질문) 수집 - Python Web Crawling
나는 정은 2022. 10. 5. 23:02멋쟁이 사자처럼 4주차
2022.10.05
서울특별시 다산콜센터 자주 묻는 질문 데이터 수집 (웹 크롤링)
목록 > 120주요질문 > 시민소통 > 정보소통광장
목록
opengov.seoul.go.kr
작성할 코드 구성
# Pseudo Code
"""
120 주요질문의 특정 페이지 목록을 수집
1) page_no 마다 url이 변경되도록 f-string을 만든다.
2) requests 를 사용해서 요청을 보내고 응답받는다.
3) pd.read_html를 사용해서 table tag로 게시글을 읽는다.
4) 3번 결과에서 0번 index를 가져와 데이터프레임 목록의 내용을 채운다.
5) html tag를 파싱할 수 있도록 bs 형태로 만든다.
6) 목록 안에 있는 a tag를 찾는다.
7) a tag 안의 string을 분리한 뒤 내용 번호만 뽑아 리스트 형태로 만든다.
8) 4의 결과에 내용번호라는 변수를 만들어 a tag 리스트를 추가한다.
"""0. 라이브러리 로드
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
import time
import numpy as np1. 크롤링할 내용 확인
# 120 다산 콜센터의 첫 페이지를 먼저 불러와 크롤링할 내용을 봅니다.
base_url = "https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page=1"
print(base_url)# pd.read_html 을 통해 해당 URL의 table 정보 리딩
table = pd.read_html(base_url, encoding='utf-8')
table[0][:5]- pd.read_html() : 웹 페이지를 구성하는 html 소스코드에서 table 속성에 해당하는 값들을 가져온다.

2. 상세 정보를 위한 링크 정보 수집
# 웹 페이지 요청 및 결과를 저장
response = requests.get(base_url)
response.status_code- get() : 필요한 데이터를 Query String에 담아 전송한다.
- post() : 전송할 데이터를 HTTP 메세지의 body - From Data에 담아 전송한다.
- get과 post 여부는 브라우저 Network tab 의 Headers > Request Method 를 통해 확인할 수 있다.
- status_code : 응답코드 확인
- Response 200 == 'OK'
3. BeautifulSoup를 사용하여 HTML 소스코드 파싱
html = bs(response.text)4. 소스코드 내 정보 탐색 및 수집
a_list = html.select('td.data-title.aLeft > a')
a_list[:5]- BeautifulSoup. select() : html 소스코드에서 원하는 데이터가 담긴 태그 찾기
[<a href="/civilappeal/26695536">하반기 농부의 시장 일정은 어떻게 되나요?</a>,
<a href="/civilappeal/25670204">다자녀가정 실내 바닥매트 지원</a>,
<a href="/civilappeal/23194045">[서울산업진흥원] 서울메이드란?</a>,
<a href="/civilappeal/22477798">마포 뇌병변장애인 비전센터</a>,
<a href="/civilappeal/21212235">위드유 서울 직장 성희롱.성폭력 예방센터</a>]-
- a 태그 안의 상세 페이지 접근을 위한 링크 번호 수집
- 태그 맨 마지막에 있는 일련번호를 수집한다.
- a 태그 안의 상세 페이지 접근을 위한 링크 번호 수집
a_list[1]['href'].split('/')[-1]'25670204'5. 파생 변수 생성
"내용번호"라는 새로운 컬럼 추가하기
a_link_no = []
for i in a_list:
a_link_no.append(i['href'].split('/')[-1])table[0]['내용번호'] = a_link_no
table[0].head()
서울시 다산콜센터 페이지 하나에 저장된 민원 게시글의 제목을 모두 수집해왔다.
이 과정을 모든 페이지에 적용시키기 위한 함수를 만들고, 2304개에 해당하는 게시글의 제목을 수집해보았다.
모든 페이지를 탐색하여 데이터 수집
def get_one_page(page_no):
base_url = f"https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page={page_no}"
response = requests.get(base_url)
table = pd.read_html(response.text, encoding='utf-8')[0]
if table.shape[0] == 0:
return f'Error : {page_no} 페이지를 찾을 수 없습니다.'
try:
html = bs(response.text)
a_list = html.select('td.data-title.aLeft > a')
a_link_no = [a_tag['href'].split('/')[-1] for a_tag in a_list]
table['내용번호'] = a_link_no
except:
return f"{page_no} 페이지를 찾을 수 없습니다."
return tablepage_no = 1
table_list = []
while True:
df_t = get_one_page(page_no)
if type(df_t) == str:
print(f"\n{page_no-1}페이지끼지 수집 완료")
break
print(page_no, end =', ')
table_list.append(df_t)
page_no += 1
time.sleep(0.01)- 모든 페이지에 대해 수집하기 위해 예외처리를 적용한다. (try ~ except 구문)
- 페이지를 불러올 수 없을 경우 문자열을 return하도록 한다.
- 무한 반복문을 순회하면서 함수 반환 값이 문자열이 아닐 때까지 웹 페이지를 탐색한다.
- 페이지를 불러올 수 없을 경우 문자열을 return하도록 한다.
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44,
45, 46, 47
47페이지끼지 수집 완료- 총 47 페이지, 2304 개에 해당하는 게시글 데이터 수집
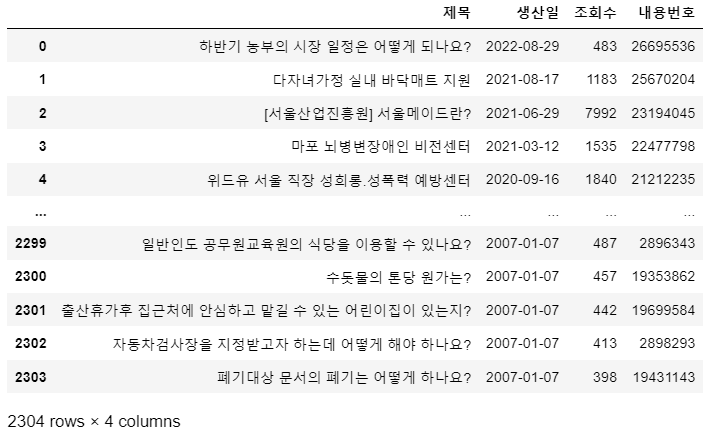
데이터 병합 및 저장
# 저장할 파일명
file_name = "seoul-120-list.csv"
df.to_csv(file_name , index=False)
# 데이터 불러오기
test = pd.read_csv(file_name)자주 들어가는 단어 워드클라우드 시각화

- 지원, 계획, 사업, 시설, 운영, 문의 , 신청 등의 단어들이 눈에 띈다
'Data Science > Side' 카테고리의 다른 글
| [KDT] 서울시 코로나19 데이터 발생동향 EDA - 2 (0) | 2022.10.13 |
|---|---|
| [KDT] 서울시 코로나19 데이터 발생동향 EDA - 1 (0) | 2022.10.12 |
| [KDT] 서울시 다산콜센터(☎120)의 질문 답변 내용 수집 - Python Web Crawling (0) | 2022.10.06 |
'Data Science/Side' Related Articles
more



Comments