[KDT] Students Academic Performance Prediction (ML Classification, kaggle)

🦁 LikeLion AIS7 MINI PROJECT - 3
멋쟁이 사자처럼 미니프로젝트 : 분류 예측 ML
프로젝트 기간 : 2022-10-31 ~ 2022-11-06
Dataset 출처
Students' Academic Performance Dataset
xAPI-Educational Mining Dataset
www.kaggle.com
: kaggle Students' Academic Performance Dataset
Kalboard 360이라는 학습 관리 시스템(LMS)에서 수집한 교육용 데이터 세트
Feature : 세 가지 주요 Part로 분류
(1) 성별 및 국적과 같은 인구통계학적 특징.
-
- 성별 : 305명의 남성과 175명의 여성으로 구성
- 국적 : 쿠웨이트 179명, 요르단 172명, 팔레스타인 28명, 이라크 22명, 레바논 17명, 튀니스 12명, 사우디 아라비아 11명, 이집트 &시리아 학생 7명, 미국, 이란, 리비아 학생 6명, 모로코 학생 4명, 베네수엘라 학생 1명.
(2) 학력, 학년, 섹션 등의 학력 특징.
-
- 학기 : 첫 번째 학기에 245개 두 번째 학기에 235개 학생 기록이 수집
(3) 수업에 손들기, 리소스 열기, 학부모 설문조사 응답, 학교 만족도와 같은 행동 특징.
-
- 결석일에 따라 191명의 학생이 7일을 초과하고 289명의 학생이 7일 미만인 두 가지 범주로 분류되는 등 출석 관련 데이터 포함
- 교육 과정에서 부모의 참여 또한 살펴본다.
- 학부모 응답 설문조사와 학부모 학교 만족도의 두 가지 하위 부분에 대한 설문 조사에 응답한 학부모는 270명이고 210명이 응답하지 않았다.
- 292명의 학부모가 학교에 만족하고 188명이 그렇지 않다.
- 교육 과정에서 부모의 참여 또한 살펴본다.
- 결석일에 따라 191명의 학생이 7일을 초과하고 289명의 학생이 7일 미만인 두 가지 범주로 분류되는 등 출석 관련 데이터 포함
각 Columns 설명
- gender: 학생의 성별 (M: 남성, F: 여성)
- NationaliTy: 학생의 국적
- PlaceofBirth: 학생이 태어난 국가
- StageID: 학생이 다니는 학교 (초,중,고)
- GradeID: 학생이 속한 성적 등급
- SectionID: 학생이 속한 반 이름
- Topic: 수강한 과목
- Semester: 수강한 학기 (1학기/2학기)
- Relation: 주 보호자와 학생의 관계
- raisedhands: 학생이 수업 중 손을 든 횟수
- VisITedResources: 학생이 과목 공지를 확인한 횟수
- Discussion: 학생이 토론 그룹에 참여한 횟수
- ParentAnsweringSurvey: 부모가 학교 설문에 참여했는지 여부
- ParentschoolSatisfaction: 부모가 학교에 만족했는지 여부
- StudentAbscenceDays: 학생의 결석 횟수 (7회 이상/미만)
- Class: 학생의 성적 등급 (L: 낮음, M: 보통, H: 높음)
0. 라이브러리 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
from scipy import stats
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix1. Data 확인
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 480 entries, 0 to 479
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gender 480 non-null object
1 NationalITy 480 non-null object
2 PlaceofBirth 480 non-null object
3 StageID 480 non-null object
4 GradeID 480 non-null object
5 SectionID 480 non-null object
6 Topic 480 non-null object
7 Semester 480 non-null object
8 Relation 480 non-null object
9 raisedhands 480 non-null int64
10 VisITedResources 480 non-null int64
11 AnnouncementsView 480 non-null int64
12 Discussion 480 non-null int64
13 ParentAnsweringSurvey 480 non-null object
14 ParentschoolSatisfaction 480 non-null object
15 StudentAbsenceDays 480 non-null object
16 Class 480 non-null object
dtypes: int64(4), object(13)
memory usage: 63.9+ KBdf.shape(480, 17)2. EDA
a. 수치형 데이터 EDA
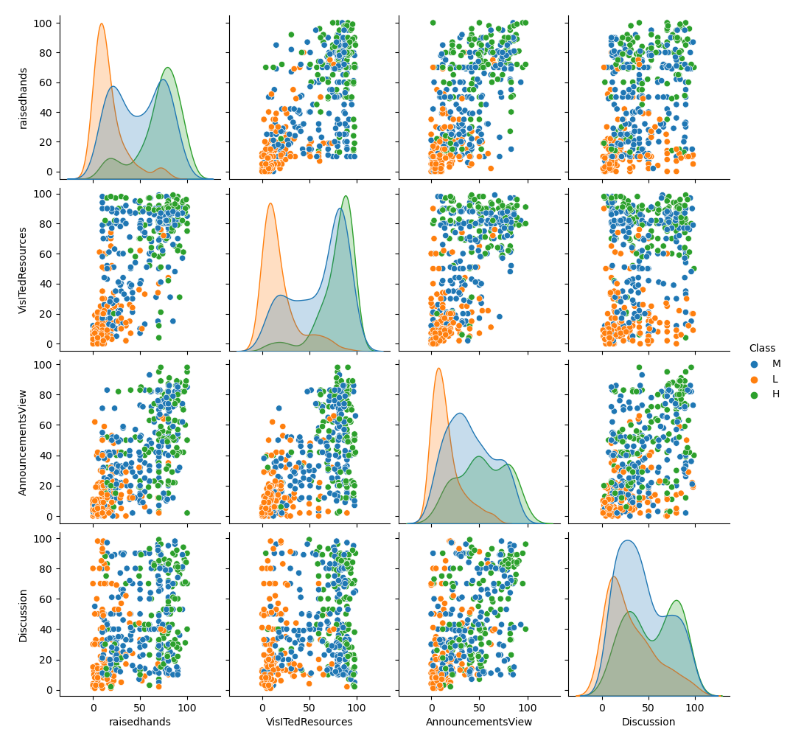
- 17개의 컬럼 중 4개의 수치형 데이터에서 이상치는 발견되지 않았다.
- 클래스별 구분이 어느 정도 뚜렷한 것으로 판단되었다.
b. 범주형 데이터
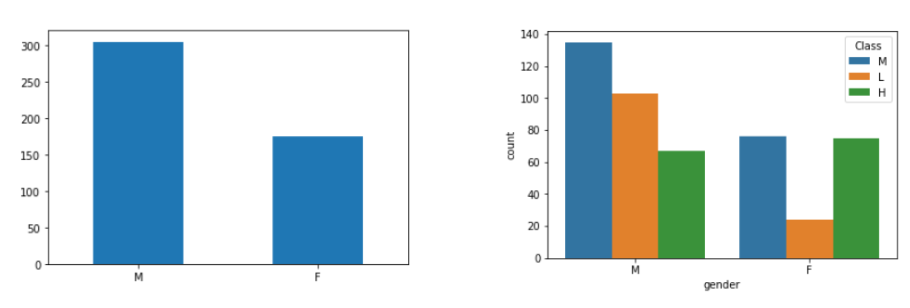
성별의 경우 남성의 빈도 수가 더 높지만 성적이 우수한 사람의 비율은 여자가 더 많았다.
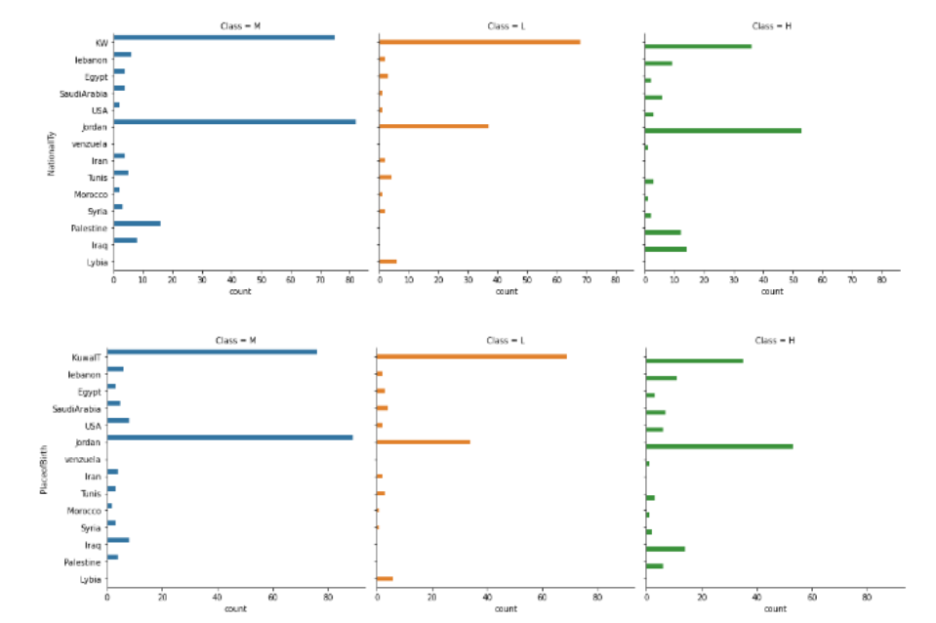
- 국적과 출생지의 경우 비슷한 양상을 보이고 , 이민으로 인한 국적 변동이 있었던 사람의 수가 아주 적어서 변수를 하나로 합쳐주었다.
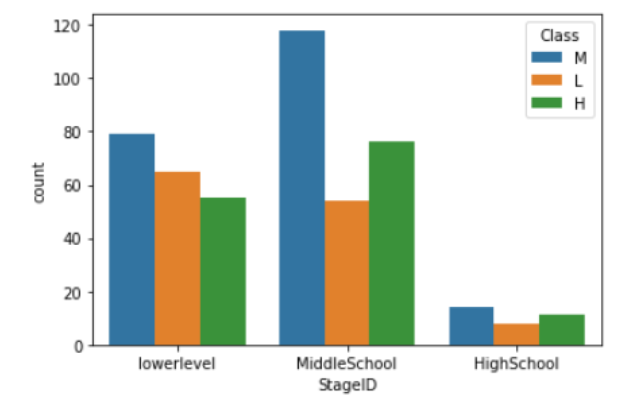
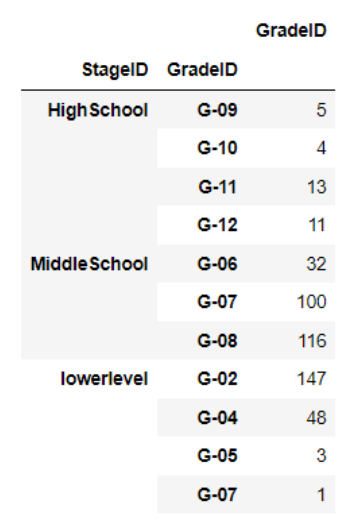
- G-02 ~ G-05는 lowerlevel, G-06~G-08은 MiddleSchool, G-09~G-12는 HighScholl에 포함되는 것을 알 수 있으며 두 변수 간의 상관성이 높을 것이라 추측해볼 수 있다.
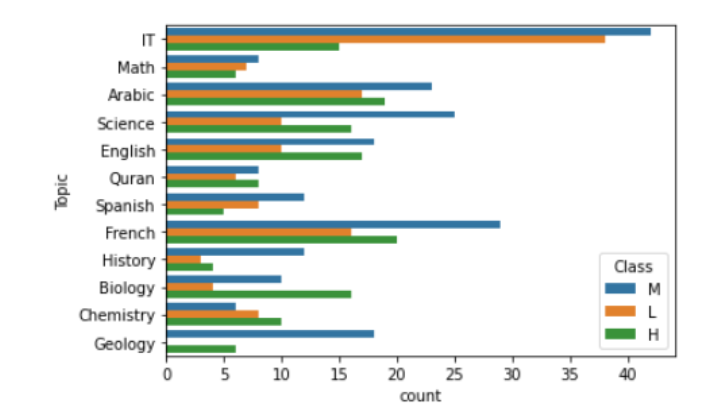
- 상위권 학생들은 IT 또는 수학 과학 교과목을 잘한다.
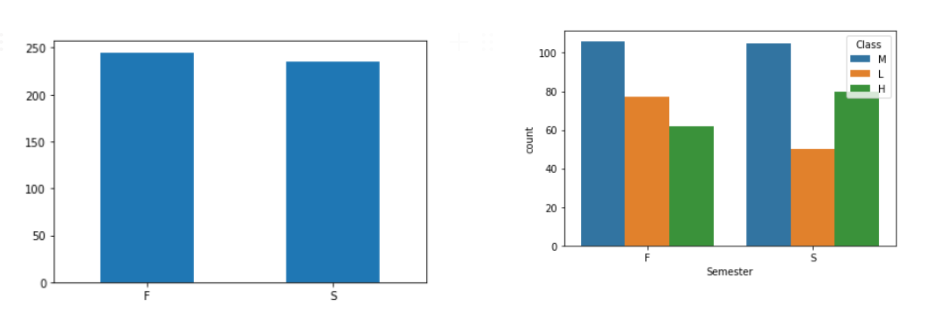
- 학기 같은 경우 별다른 변화는 없지만 하위권이 줄어들었고 상위권 학생이 약간 증가했다.
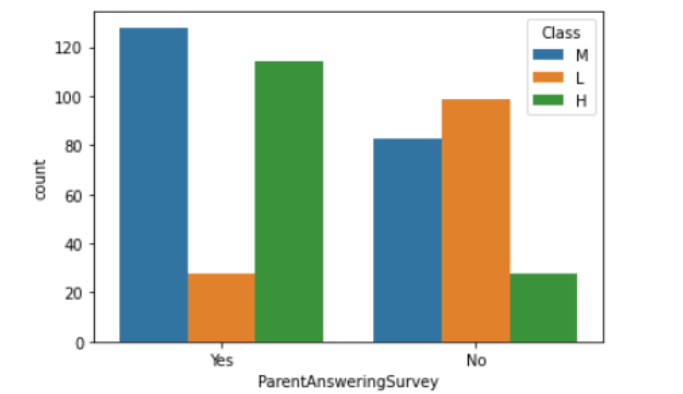
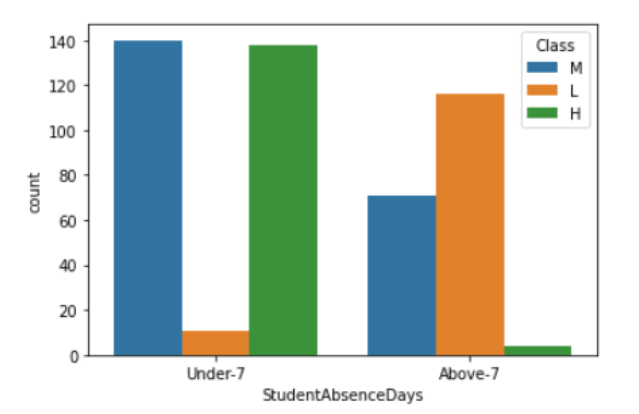
- 학교 설문에 적극 답변한 부모님의 자녀들은 중상위권에 속하며, 중상위권 학생들의 경우 결석이 7회 이하인 비중이 더 높았다.
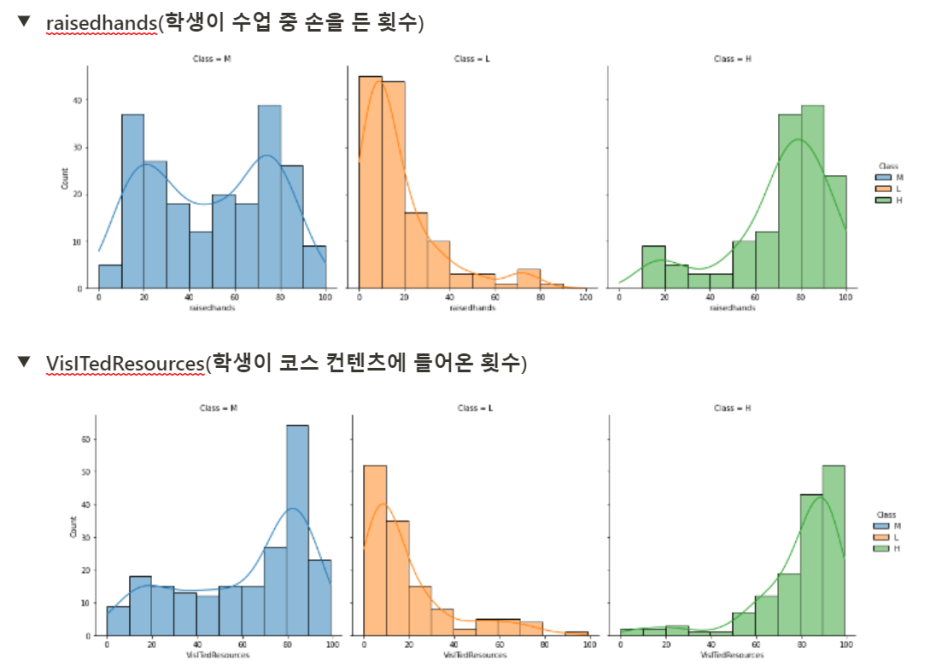
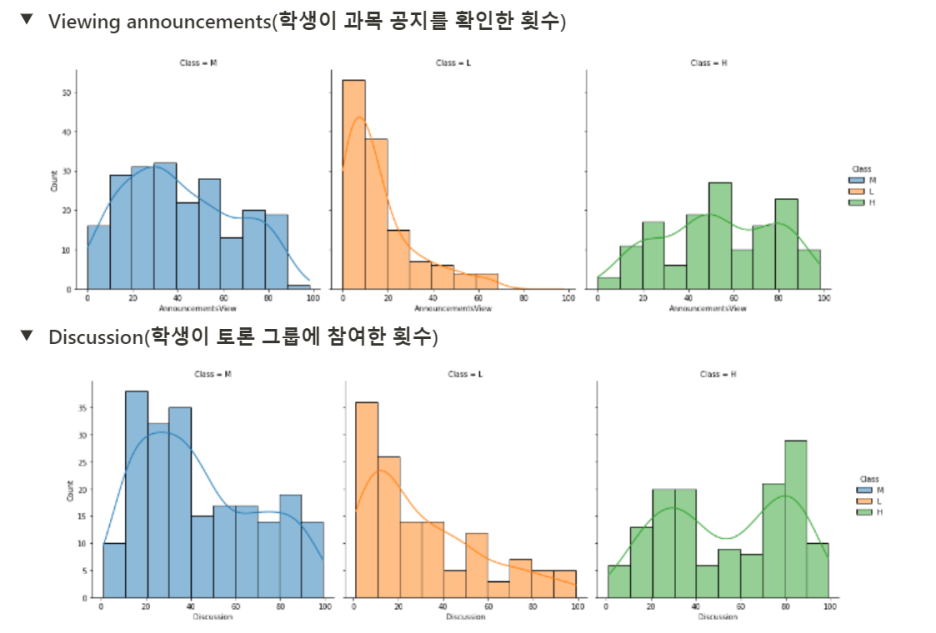
- 전반적인 학교 생활에 관심을 가지고 참여하는 학생들은 중상위권
- 하위권 학생들은 대체적으로 수업 컨텐츠 참여도가 낮다.
3. Feature Engineering
- 위에서 분석한 내용을 바탕으로 어떤 변수를 선택할 지, 어떤 변수를 조정할 지를 생각하였다.
a. "Class" 변수 Label Encoding
df["Class"].unique()array(['M', 'L', 'H'], dtype=object)df["Class"].unique() # ['M', 'L', 'H']
classid = {'M':0, 'L':-1, 'H':1}
df["class_fill"] = df["Class"].copy()
df["class_fill"] = df["Class"].map(classid)
df[["Class", "class_fill"]].sample(10)
b. Drop Feature
df = df.drop(columns=['Class','NationalITy', 'PlaceofBirth', 'GradeID'])
df.head(2)- 국적, 등급명, label을 제외한 데이터셋으로 머신러닝 진행
df.columns
Index(['gender', 'StageID', 'SectionID', 'Topic', 'Semester', 'Relation',
'raisedhands', 'VisITedResources', 'AnnouncementsView', 'Discussion',
'ParentAnsweringSurvey', 'ParentschoolSatisfaction',
'StudentAbsenceDays', 'class_fill'],
dtype='object')c. One - Hot Encoding
mod_df = pd.get_dummies(df,drop_first = True)
mod_df.shape #(480, 26)
mod_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 480 entries, 0 to 479
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 raisedhands 480 non-null int64
1 VisITedResources 480 non-null int64
2 AnnouncementsView 480 non-null int64
3 Discussion 480 non-null int64
4 Class 480 non-null int64
5 gender_M 480 non-null uint8
6 StageID_MiddleSchool 480 non-null uint8
7 StageID_lowerlevel 480 non-null uint8
8 SectionID_B 480 non-null uint8
9 SectionID_C 480 non-null uint8
10 Topic_Biology 480 non-null uint8
11 Topic_Chemistry 480 non-null uint8
12 Topic_English 480 non-null uint8
13 Topic_French 480 non-null uint8
14 Topic_Geology 480 non-null uint8
15 Topic_History 480 non-null uint8
16 Topic_IT 480 non-null uint8
17 Topic_Math 480 non-null uint8
18 Topic_Quran 480 non-null uint8
19 Topic_Science 480 non-null uint8
20 Topic_Spanish 480 non-null uint8
21 Semester_S 480 non-null uint8
22 Relation_Mum 480 non-null uint8
23 ParentAnsweringSurvey_Yes 480 non-null uint8
24 ParentschoolSatisfaction_Good 480 non-null uint8
25 StudentAbsenceDays_Under-7 480 non-null uint8
dtypes: int64(5), uint8(21)
memory usage: 28.7 KBd. Feature Scaling - StandardScaler
- 원핫인코딩된 변수들과 범위를 맞추기 위해 4개의 수치변수에 대한 스케일링을 적용
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
mod_df['raisedhands'] = preprocessing.scale(mod_df['raisedhands'])
mod_df['VisITedResources'] = preprocessing.scale(mod_df['VisITedResources'])
mod_df['AnnouncementsView'] = preprocessing.scale(mod_df['AnnouncementsView'])
mod_df['Discussion'] = preprocessing.scale(mod_df['Discussion'])
mod_df[['raisedhands', 'VisITedResources', 'AnnouncementsView', 'Discussion']].sample(10)
e. Selected Feature
corr = mod_df.corr()
mask = np.triu(np.ones_like(corr))
plt.figure(figsize = (15,8))
sns.heatmap(corr, cmap = "coolwarm", annot=True, mask = mask,fmt='.3f')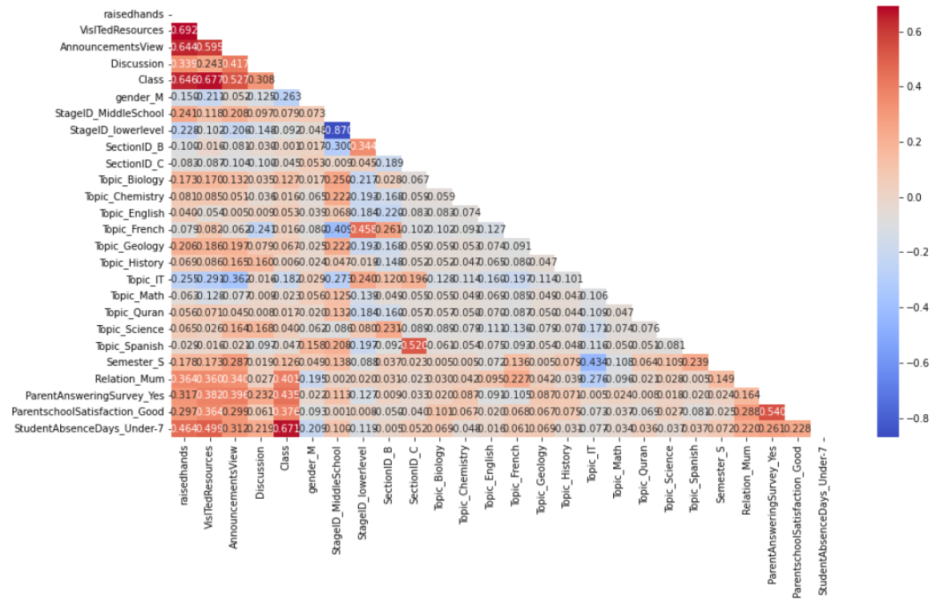
4. Modeling
a. train -test set 분리
# test에 사용할 컬럼명
label_name = "Class"
# train에 사용할 컬럼명
feature_names = mod_df.columns.tolist()
feature_names.remove("Class")train = mod_df[feature_names]
print(train.shape) #(480, 25)
display(train.head(2))
test = mod_df[label_name]
print(test.shape) #(480, )
display(test.head(2))
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train, test,
test_size=0.2,random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
b. 사용한 머신러닝 분류 모델
|
알고리즘
|
장점
|
단점
|
|
k-최근접 이웃
(K-Nearest Neighbor, K-NN) |
- 구현이 쉽다
알고리즘을 이해하기 쉽다 - 하이퍼파라미터가 적다 |
- 예측 속도가 느리다
- 메모리를 많이 쓴다 - 노이즈 데이터에 예민하다 |
|
의사결정트리
(Decision Tree) |
- 모델의 추론 과정을 시각화하기 쉽다
- 데이터에서 중요한 특성이 무엇인지 쉽게 알아낼 수 있다 - 학습 및 예측 속도가 빠르다 |
- 과대적합되기 쉽다
- 조정해야 할 하이퍼파라미터가 많다 |
|
랜덤포레스트
(Random Forest) |
- 앙상블 효과로 의사결정트리의 과대적합 단점을 보완한다
|
- 조정해야 할 하이퍼파라미터가 많다
|
|
XGBoost
|
- 과적합 방지가 잘되어 있다.
- 예측 성능이 좋다 |
- 작은 데이터에 대해 과적합 가능성이 있다.
- 해석이 어렵다 |
|
로지스틱회귀
(Logistic Regression) |
- 데이터를 분류할 때 확률을 제공한다
|
- 데이터 특징이 많을 경우 학습이 어려워 과소적합되기 쉽다
|
c. 학습 및 예측
clf = MODEL()
result = clf.fit(X_train, y_train)
y_predict = model.predict(X_test)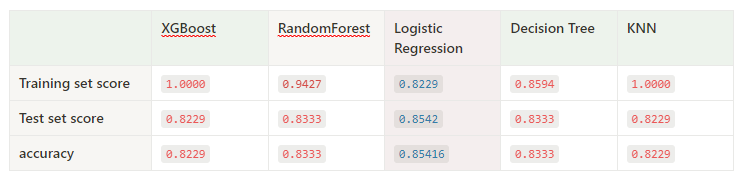
가장 Score 가 높았던 모델은 로지스틱 회귀모델이었다
Logistic Regression Classification Report
report = classification_report(y_test, y_predict,
target_names=['L', 'M', 'H'])
print(report) precision recall f1-score support
L 0.84 1.00 0.91 26
M 0.89 0.81 0.85 48
H 0.81 0.77 0.79 22
accuracy 0.85 96
macro avg 0.84 0.86 0.85 96
weighted avg 0.86 0.85 0.85 965. Fine-tuning the model
- 이전 코드에서는 5개의 모델을 선택하여 각자 학습시켰지만 5개의 모델을 모두 활용하여 하나의 모델을 설계한 앙상블기법을 사용해보았다.
- 최고의 성능을 내는 하이퍼 파라미터(Hyperparameter) 조합을 찾은 다음 앙상블 기법을 사용하여 가장 최적화된 모델을 탐색한다.
- 앙살블 기법은 "집단지성" 으로 부터 아이디어를 얻은 알고리즘으로 모델 하나의 예측 보다는 여러 모델들의 예측을 종합하여 조금 더 정확한 결과를 출력한다는 장점을 가진다.
- sklearn 패키지의 VotingRegressor 메소드를 통해 앙상블 모델을 구현한다.
- GridSearchCV 를 통해 각 모델들의 최적의 파라미터들을 찾아 저장한다.
- 그 다음 VotingRegressor 객체에 할당하여 학습을 진행하여 하나의 점수를 구한다.
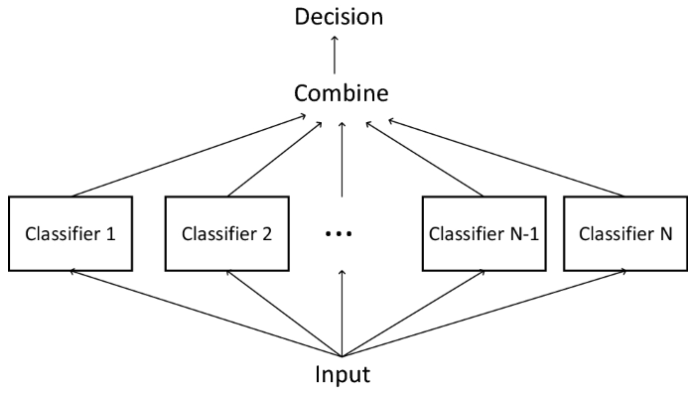
a. 하이퍼 파라미터 최적화 - GridSearchCV
- 하이퍼 파라미터 최적화를 수행하는 전통적인 방법
- 그리드 검색 또는 매개 변수 스윕으로, 학습 알고리즘의 하이퍼 파라미터 공간에서 수동으로 지정된 하위 집합을 통해 전체적으로 검색한다.
#GridSearchCV 를 사용할 모델들을 호출합니다.
from sklearn.model_selection import GridSearchCV
#모델들을 할당할 리스트를 만들어줍니다.
estimators = []
#estimators 리스트에 모델들을 추가해줍니다.
logreg = LogisticRegression()
estimators.append(logreg)
rf = RandomForestClassifier()
estimators.append(rf)
knn = KNeighborsClassifier()
estimators.append(knn)
dct = DecisionTreeClassifier()
estimators.append(dct)
xgb = XGBClassifier()
estimators.append(xgb)
#모들의 파라미터들을 할당할 리스트를 만들어줍니다.
params = []
# params 리스트에 성능을 비교하고자하는 파라미터들 추가해줍니다.
penalty = ['l1','l2']
c = [0.01, 0.1, 1, 1, 5, 10]
max_iter = list(range(100, 1100, 100))
n_jobs = [-1, 1]
params_logreg = {'max_iter':max_iter,
'C':c,
'penalty':penalty,
'n_jobs':n_jobs}
params.append(params_logreg)
params_rf = {'n_estimators' : [200],
'max_depth':[5,10,15,20],
'max_samples' : [0.2, 0.4, 0.7, 0.8, 0.9, 1.0],
'max_features':[0.2, 0.4, 0.7, 0.8, 0.9, 1.0]}
params.append(params_rf)
params_knn = {
'n_neighbors' : list(range(1,20)),
'weights' : ["uniform", "distance"],
'metric' : ['euclidean', 'manhattan', 'minkowski']
}
params.append(params_knn)
params_dct = {
'criterion':['gini','entropy'],
'max_depth':[None,2,3,4,5,6],
'max_leaf_nodes':[None,2,3,4,5,6,7],
'min_samples_split':[2,3,4,5,6],
'min_samples_leaf':[1,2,3],
'max_features':[None,'sqrt','log2',3,4,5]
}
params.append(params_dct)
params_xgb = {
'n_estimators' : [100,200],
'learning_rate' : [0.01,0.05,0.1,0.15],
'max_depth' : [3,5,7,10,15],
'gamma' : [0,1,2,3],
'colsample_bytree' : [0.5,0.8],
'objective':['binary:logistic','multi:softprob'],
'missing':[9999]
}
params.append(params_xgb)`5/5 [11:23<00:00, 219.13s/it]`
`Fitting 5 folds for each of 240 candidates, totalling 1200 fits
Fitting 5 folds for each of 144 candidates, totalling 720 fits
Fitting 5 folds for each of 114 candidates, totalling 570 fits
Fitting 5 folds for each of 7560 candidates, totalling 37800 fits
Fitting 5 folds for each of 320 candidates, totalling 1600 fitsbest model list
[LogisticRegression(C=1, n_jobs=-1),
RandomForestClassifier(max_depth=15, max_features=0.2, max_samples=0.8,
n_estimators=200),
KNeighborsClassifier(metric='manhattan', n_neighbors=19, weights='distance'),
DecisionTreeClassifier(max_depth=6, min_samples_leaf=2),
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=0.5, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.01, max_delta_step=0, max_depth=15,
min_child_weight=1, missing=9999, monotone_constraints='()',
n_estimators=100, n_jobs=8, num_parallel_tree=1,
objective='multi:softprob', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=None, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)]b. 가장 최적화된 하나의 모델 탐색 - Voting
#GridSearchCV 를 통해 최적화된 모델들을 사용합니다.
#앙상블 기법을 위한 패키지를 불러옵니다.
model = ['lr','rf','knn','dst','xgb']
best_models = []
for n,m in zip(model,best_model_list):
best_models.append((n,m))soft Voting
- 앙상블에 사용되는 모든 분류기가 클래스의 확률을 예측할 수 있을 때 사용
- 각 분류기의 예측을 평균 내어 확률이 가장 높은 클래스로 예측 (가중치 투표)
from sklearn.ensemble import VotingClassifier
#앙상블 모델을 학습시켜줍니다.
voting_clf =VotingClassifier(estimators=best_models,voting='soft',n_jobs=-1)
voting_clf.fit(X_train,y_train)classifiers = best_model_list
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test, pred)))
voting_clf.fit(X_train, y_train)
pred = voting_clf.predict(X_test)
print('보팅 분류기의 정확도: {0: .4f}'.format(accuracy_score(y_test, pred)))LogisticRegression 정확도: 0.8542
RandomForestClassifier 정확도: 0.8750
KNeighborsClassifier 정확도: 0.7188
DecisionTreeClassifier 정확도: 0.7812
XGBClassifier 정확도: 0.8438
보팅 분류기의 정확도: 0.8333y_predict = voting_clf.predict(X_test)
accuracy = accuracy_score(y_test, y_predict)
print("accuracy: ", accuracy)
accuracy: 0.8333333333333334
Hard Voting
- 여러 모델을 생성하고 그 성과(결과)를 비교
- 이 때 classifier의 결과들을 집계하여 가장 많은 표를 얻는 클래스를 최종 예측값으로 정하는 것
voting_clf =VotingClassifier(estimators=best_models,voting='hard')LogisticRegression 정확도: 0.8542
RandomForestClassifier 정확도: 0.8542
KNeighborsClassifier 정확도: 0.7188
DecisionTreeClassifier 정확도: 0.8021
XGBClassifier 정확도: 0.8438
보팅 분류기의 정확도: 0.8542LogisticRegression 정확도: 0.8542
RandomForestClassifier 정확도: 0.8542
KNeighborsClassifier 정확도: 0.7188
DecisionTreeClassifier 정확도: 0.8021
XGBClassifier 정확도: 0.8438
보팅 분류기의 정확도: 0.85426. 성능 평가 결과
▶️ 최고 성능모델 및 가장 최적화된 하이퍼파라미터
('rf', RandomForestClassifier(max_depth=15,
max_features=0.2,
max_samples=0.8,
n_estimators=200)),Score 개선 0.8333 → 0.8750
하이퍼파라미터 최적화 : GridSearchCV 사용
Best Model : Random Forest
Best Score : 0.8333 → 0.8750
-> Voting한 점수보다 Grid Search CV를 통해 찾은 하이퍼파라미터로 만들어낸 모델의 성능이 더 좋았다.
7. Result
a. We Learned
- Feature Engineering
- 수치형 변수 스케일링
- 범주형 변수 Label Encoding
- 순서형 변수 Ordinal Encoding
- 공통되는 분야를 나누어 파생변수 만들기
- Ensemble Methods
- fine-tuning을 하는 방법에는 앙상블(Ensemble) 방법이 있다.
- 이것은 최고의 성능을 내는 모델들을 결합하는 방식이다.
- 적절한 케이스에 사용하면 각각의 모델이 내는 성능보다 뛰어난 성능을 보여주기 때문에 앞으로 조금 더 공부해서 확실하게 활용해보고 싶다.
- 최고의 모델과 오류 분석
- Decision Tree와 같은 모델에서 사용하는 방법으로 덜 중요한 요소들은 제거하여 사용하지 않는(Dropping) 방법을 사용
- feature_importnaces_를 사용하여 요소들의 중요도를 파악하였다.
- Test Set에서 모델의 성능을 평가
- 최종적인 모델을 분리했던 Test dataset을 사용하여 평가
- Test data를 Train 전처리 방식과 동일하게 적용하여 데이터를 변환시킨 후 해당 모델의 점수를 확인해야한다.
- 테스트 데이터를 학습 시킨 후 인코딩과 정규화를 진행하면 data leakage 에 해당되므로 주의해야한다는 점도 새롭게 알게 되었다.
- 훈련 또는 검증에서는 좋은 평가를 받았지만, 테스트 데이터 세트에서는 점수가 떨어지는 경우도 있어 과적합(overfitting)이 발생했다고 볼 수 있었다.
b. 개선점
-
- AutoML인 Pycaret과 Wandb를 활용하면 모델 성능이 어떻게 달라지는 지 궁금하다.
- Train, Test 를 Valid 데이터 셋까지 추가해서 실제 시험 데이터에서 예측력이 어떻게 달라질지도 한번 검증해보면 좋겠다.
- xgboost를 쓰면서 과소적합이 발생할 때의 해결 방안을 찾아보자.
- Grid Search와 Randomized SearchCV 둘 다 적용시켜보고 속도와 성능이 얼마나 달라지는 지 비교해보자.
- 분류 모델 성능 평가 Matrix에 대한 설명을 추가할 수 있으면 좋을 것 같다 .
- Voting 앙상블이 예상 외로 점수가 그렇게 만족스럽지 않았는데 그 이유를 알고 싶다.
🎃 세 번째 미니 프로젝트 회고
세 번째 미니프로젝트가 끝이 났다!
작년에 무지성으로 참여했던 Dacon의 기억을 떠올리면서 프로젝트를 진행했는데
생각보다 더 헷갈리고 어려웠던 것 같다.
그 때는 베이스라인을 제대로 이해하지도 못한 채로 있는 코드 다 갖다 붙여 어찌저찌 결론내고
Train과 Test를 나눈 다음 어떻게 예측에 활용되는지조차 헷갈렸었는데
확실히 교육을 한 번 받고 동료들과 의견을 나누면서 하는 게 도움이 정말 많이 되었던 것 같다.
팀원분들의 피드백으로 내가 잘못 이해하고 있었던 부분을 수정하고 모델을 예측하는 과정을 좀 더 확실하게 알아갈 수 있었던 것 같다
그래도 그리드서치부터 앙상블(보팅)까지 배웠던 내용들을 직접 내가 적용해볼 수 있었고, 결론까지 도출해낼 수 있었다는 점이 가장 뿌듯하다.
이번엔 개선점을 따로 정리를 했는데 아직 배워야할 것들이 산더미인 것 같다.
좀 더 공부를 해보고 4번째 프로젝트에 임하도록 하겠다 !!!
화이팅 !!!