[KDT] YouTube API를 활용하여 수집한 데이터 분석하기 (2) KoNLPy 단어 형태소 추출 & WordCloud 시각화
멋쟁이 사자처럼 AI스쿨 7기
제 1회 미니 프로젝트 회고 - 2 (2022-09-26 ~ 2022-10-03)
유튜브 API 데이터 분석 : KoNLPy를 이용한 한글 데이터 워드클라우드 시각화

유튜브 API를 활용하여 수집한 데이터 분석하기
분석할 유튜브 채널 선정
- 요즘 자주 시청하고 있는 인생 상담 유튜버 "김달" 님 채널의 데이터를 수집하였다.
- https://www.youtube.com/c/%EA%B9%80%EB%8B%AC (짱 재밌음 강추)
- 구독자 80만명, 업로드된 동영상이 총 790개로 데이터를 분석하기에 적합하다는 생각이 들었다.
- https://www.youtube.com/c/%EA%B9%80%EB%8B%AC (짱 재밌음 강추)
수집한 데이터
1) Youtube_김달_video_20221004_v0.csv
channel = '김달'
name = "김달" # file_name에 쓰일 채널명
df_channel_info = get_channel_info(channel, API_KEY, name)
df_channel_info- 전체 채널에 업로드된 영상 791개의 정보 수집
- video_id : 영상 Id key값
- title : 영상 제목
- date : 업로드 날짜
- view : 조회수
- likecnt : 좋아요수
- comment : 댓글 수
- channel_name : 김달
2) Youtube_h0fdxOOhs8g_comments_20221004_v0.csv
video_id = df.sort_values(by=['comment'],ascending = False,ignore_index=True)['video_id'][0]
video_name = df.sort_values(by=['comment'],ascending = False,ignore_index=True)['title'][0]
get_comments(video_id, video_name ,API_KEY)총 20 page의 댓글을 수집했습니다.
총 2004개의 댓글을 수집했습니다.
- 가장 댓글 수가 많았던 영상의 댓글 데이터 2004개 수집
- comment : 댓글 내용
- author : 댓글 작성자
- datetime : 작성 시간
- like_count : 좋아요 수
0. 라이브러리 로드
# 라이브러리 로드
import numpy as np
import pandas as pd
from datetime import datetime as dt
from googleapiclient.discovery import build
import os
import warnings # 경고창 무시
warnings.filterwarnings('ignore')
# 시각화 라이브러리
from wordcloud import WordCloud # 워드클라우드 호출
import matplotlib.pyplot as plt # 워드클라우드 시각화
import seaborn as sns
from collections import Counter # 텍스트 및 빈도수 추출
from konlpy.tag import Okt # 한국어 형태소 분석 패키지
from PIL import Image # 워드클라우드 원하는대로 그리기
# font 설정 관련 라이브러리
import matplotlib.font_manager as fm
font = "./NanumBarunGothicLight.ttf" # ttf가 저장된 경로
font_family = fm.FontProperties(fname=font).get_name() # 경로 강제 포맷
# 한글폰트
plt.rc("font", family=get_font_family())1. 데이터 읽어오기
csv 파일 불러오기
# 파일 불러오기
df_video = pd.read_csv('Youtube_김달_video_20221004_v0.csv', dtype={"itemcode":"object"})
df_comment = pd.read_csv(f'Youtube_comment_{video_title}_20221004_v0.csv', dtype={"itemcode":"object"})- pd.read_csv : csv파일을 읽어옴
df_video.head()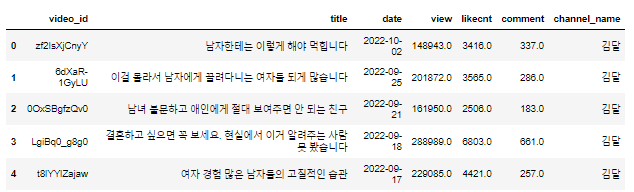
df_comment.head()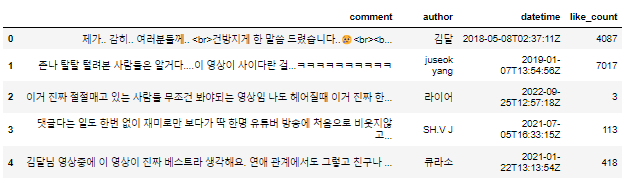
- head() : 상위 5개 행 출력
- tail() : 하위 5개 행 출력
데이터 확인하기
df_video.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 790 entries, 0 to 789
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 video_id 790 non-null object
1 title 790 non-null object
2 date 790 non-null object
3 view 790 non-null float64
4 likecnt 790 non-null float64
5 comment 790 non-null float64
6 channel_name 790 non-null object
dtypes: float64(3), object(4)
memory usage: 43.3+ KB
df_comment.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2004 entries, 0 to 2003
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 comment 2004 non-null object
1 author 2004 non-null object
2 datetime 2004 non-null object
3 like_count 2004 non-null int64
dtypes: int64(1), object(3)
memory usage: 62.8+ KB- df.info() : 두 데이터 모두 null값 없이 데이터가 잘 수집되었음을 확인할 수 있다 !
- date , datetime 변수의 경우 시간과 관련된 데이터이므로 datatime 자료형으로 변환시켜준다.
df_video['date'] = pd.to_datetime(df_video["date"])
df_video["year"] = df_video["date"].dt.year
df_video["month"] = df_video["date"].dt.month- pd.to_datetime() : 데이터의 type을 시계열 자료형으로 변환시킨다.
- year , month 를 따로 추출하여 새로운 파생 변수를 생성해주었다.
데이터 통계량 확인
pd.set_option('display.float_format', '{:.1f}'.format)
df_video.describe()- pd.set_option() 을 지정해주면 과학적 표기법을 해제할 수 있다.

2. 수치형 자료 변수 EDA
기간 별 영상 업로드 개수의 변화
연도별 영상 개수의 변화 - countplot
sns.countplot(data = df_video, x="year")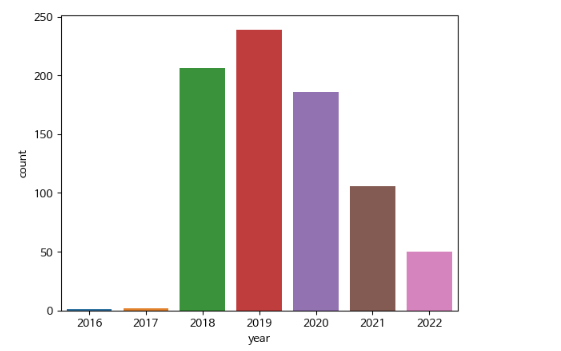
- 2018년부터 본격적으로 영상을 업로드 하기 시작하였음을 알 수 있었다 !
- 2020년부터 조금씩 영상 업로드 주기를 늦춘 것으로 보인다.
2016 ~ 2022년 사이 월 별 영상 업로드 개수 변화
sns.countplot(data = df_video, x="month",hue='year')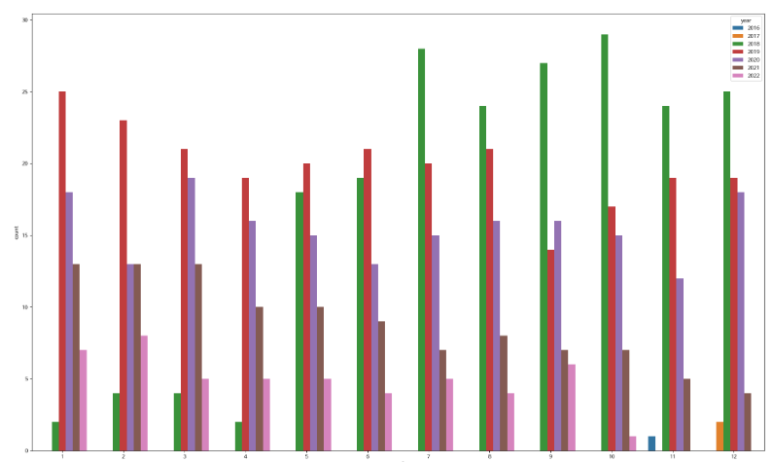
- 2018년 여름부터 2021년 봄까지 영상 업로드 개수가 줄어들었다.
- 이걸 좀 더 가독성 있게 그래프를 바꿔보도록 하자.
데이터 전처리 1.
: "year-month" 형태의 새로운 파생 변수 생성
def make_ym(datetime):
year = str(datetime.year)
month = datetime.month
if month < 10:
month = '0'+str(month)
return year + '-' + str(month)
df_video['year_month'] = df_video['date'].apply(make_ym)
df_video
- 년-월을 붙여서 한번 출력해보도록 하자!
fig, ax = plt.subplots(figsize=(25,15))
sns.countplot(data = df_video, x="year_month")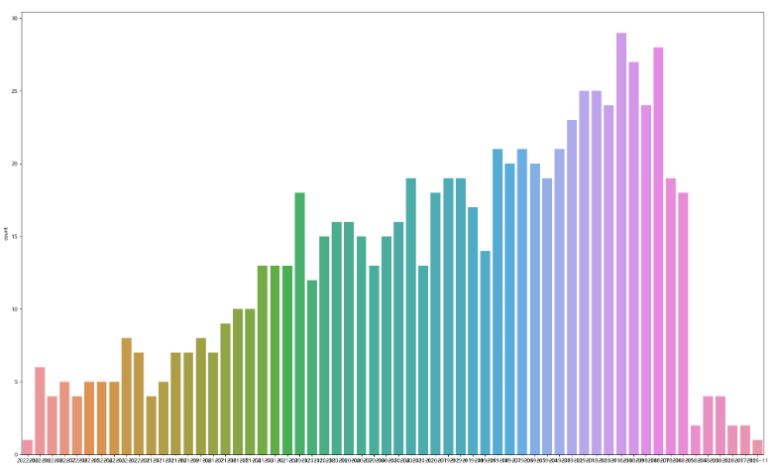
- 범위를 쪼개주지 못해서 x축이 많다.
- 2016년 11월부터 2022년 10월까지의 월별 영상 업로드 개수에 대한 count plot을 출력해보았다.
2016 ~ 2022년 사이 월 별 영상 조회수와 좋아요수 변화
df_view = df_video[df_video['year'] >= 2017]
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches(18,10)
sns.pointplot(data=df_view, x="year", y="view", ax=axes[0][0], ci=None)
sns.pointplot(data=df_view, x="year", y="likecnt", ax=axes[0][1], ci = None)
sns.pointplot(data=df_view, x="month", y="view", hue = 'year', ax=axes[1][0], ci = None)
sns.pointplot(data=df_view, x="month", y="likecnt",hue = 'year', ax=axes[1][1], ci = None)
axes[0][0].set(title = '연도별 조회수')
axes[0][1].set(title = '연도별 좋아요 수')
axes[1][0].set(title = '월별 조회수')
axes[1][1].set(title = '월별 좋아요 수')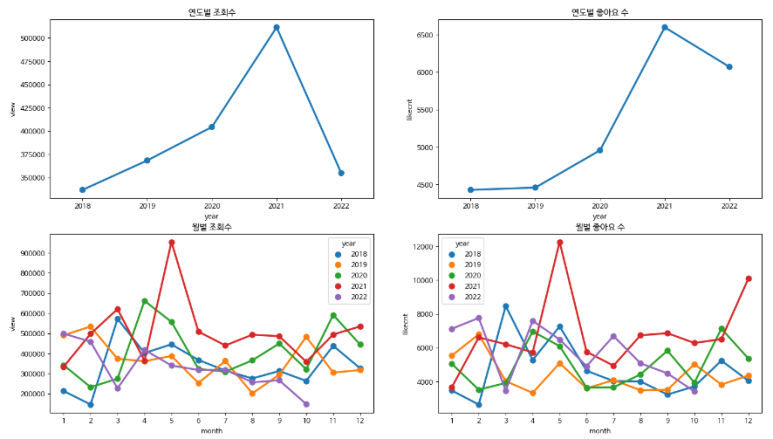
- pointplot : 값에 대한 평균을 점으로 찍고 category한 값끼리 선으로 연결한 그래프
- 2016년, 2017년 데이터가 충분히 수집되지 않아 평균값이 극단적으로 나타나 제거하고 출력했다 !
- 2018 ~ 2021 년까지 조회수와 좋아요 수가 상승하였음을 알 수 있다!
- 2016년, 2017년 데이터가 충분히 수집되지 않아 평균값이 극단적으로 나타나 제거하고 출력했다 !
3. 타이틀 주요 키워드 시각화
이 영상들이 어떻게 조회수를 끌어모았는지 알아보자.
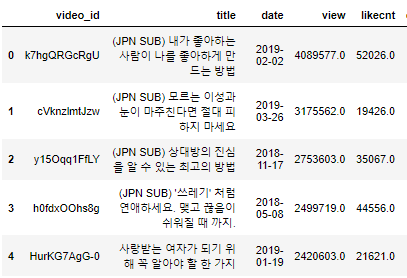
사람들이 영상을 클릭할 때는 썸네일과 타이틀을 주로 많이 보게 된다.
이 채널은 '썸네일은 곧 타이틀이다" 라는 포맷을 항상 유지하고 있었기 때문에 "타이틀이 사람들의 시선을 끌었다" 라고 가정하였다.
조회수가 평균 이상을 기록한 영상들의 타이틀을 분석하여
타이틀을 구성하는 단어들의 주요 키워드를 워드 클라우드라는 tool을 사용하여 시각화하였다.
Konly 를 활용한 Word Cloud 시각화
- 조회수 평균 이상을 기록한 영상 타이틀들의 주요 키워드
Konlpy 설치
!pip install konlpy형태소 분석 및 수집
texts = []
words = []
Words = []
okt = Okt()
for i in range(len(df)):
texts.append(df['title'][i])
for text in texts:
words = okt.pos(text)
words_list = [word for word, tag in words if tag in ['Noun','Ajective'] and len(word) > 1] # 단어의 길이가 1개인 것은 제외
for new_word in words_list:
Words.append(new_word)
print(f'총 {len(Words)} 개의 단어 수집')총 820 개의 단어 수집konlpy.Okt() : 타이틀 텍스트를 모두 수집한 뒤 konlpy를 이용해 명사, 형용사만 추출하도록 하였다.
- okt.pos() : 단어와 단어의 형태소를 반환한다.
- 단어 , 형태소를 비교하여 명사와 형용사인 경우만 수집하였고, 수집한 단어들은 새 리스트에 모두 넣어준다.
- 총 820개의 단어가 수집되었다.
- 단어 , 형태소를 비교하여 명사와 형용사인 경우만 수집하였고, 수집한 단어들은 새 리스트에 모두 넣어준다.
Word Cloud 만들기
# 워드클라우드 생성
c = Counter(nouns_words_list)
font = 'C:/Windows/Fonts/NanumBarunGothicLight.ttf' #한글 폰트 반환
wc = WordCloud(font_path=font, background_color='black',max_font_size=400,
mask=mask ,colormap='prism')
gen = wc.generate_from_frequencies(c)
plt.figure(figsize=(20,20)) # 사이즈 조절
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()PIL 라이브러리 : 이미지를 불러와 해당 이미지 모양 형태로 워드 클라우드를 출력할 수 있다.
- https://wonhwa.tistory.com/20 여기서 실습 코드를 확인해볼 수 있다 !

- 연애 상담 유튜버답게 조회수가 높은 영상에서는 연애 상담 내용과 관련된 키워드를 사용했다.
- ~ 하는 방법 , 절대 ~ 할 것들/ 하면 안될 것들 등등등 솔루션과 관련된 키워드들도 종종 보인다.
++) 댓글 수가 가장 많은 영상의 키워드 분석 결과
2004개 댓글 중 사람들의 공감을 많이 받은 댓글 키워드 분석
- 좋아요를 받은 개수가 1000개 이상인 댓글들을 기준으로 단어 키워드를 분석해보았다.
df_comment.shape(2004, 4)make_WordCloud(df_cmt , 'comment')
- 부정적 느낌을 주는 키워드들이 많이 보인다
- 아마 상담 영상을 시청하고 자신이 공감하고 느낀점들을 댓글로 남기는 분들이 많아서라고 추측해볼 수 있었다.
단어들로는 어떤 인사이트를 찾을지 감이 잘 오지 않았다.
동사를 기준으로 시각화를 해볼 수 있으면 좋을 것 같다 !
Reference
유튜브 API를 사용한 유튜브 댓글 크롤링
유튜브 댓글을 수집하는 방법은 크게 두 가지입니다. 첫번째는 Google에서 제공하는 유튜브 API를 사용하는 것이고, 두번째는 직접 HTML 문서에서 크롤링하는 방법이 있습니다. 이번에는 유튜브 API
velog.io
[kaggle] Bike Sharing Demand: EDA 1편
첫 번째로 시작한 kaggle 프로젝트는 바로 'Bike Sharing Demand Project' 이다. 아주 유명한 데이터셋이라 많이 들어본 분들도 있으리라 생각한다. (무려 7년 전 데이터..!) 2022년 5월 25일부터 2022년 6월 9일.
suy379.tistory.com
파이썬으로 슈카월드 유튜브 조회/좋아요/댓글 수 가져오기
저번 시간에 이어서 내 최애 유튜버 슈카월드 유튜브 채널에 대해 분석해보겠다. 아래 코드를 돌리면 슈카월드 채널에 있는 모든 동여상의 제목과 해당되는 Video ID값을 구할 수 있을 것이다. Vide
yobro.tistory.com
GitHub - googleapis/google-api-python-client: 🐍 The official Python client library for Google's discovery based APIs.
🐍 The official Python client library for Google's discovery based APIs. - GitHub - googleapis/google-api-python-client: 🐍 The official Python client library for Google's discovery based APIs.
github.com
기사 제목 크롤링을 통한 워드클라우드 시각화하기 [완료]
기쁨의 워드클라우드 탈출기. 무언가 해놓은게 없다는 판단에 배운거라도 써먹을 수 있도록 기사제목 크롤링 후 워드클라우드로 일자 별 키워드를 한눈에 볼 수 있는 코드를 짜봤다. 3월 21일에
durian9s-coding-tree.tistory.com
파이썬(Python) - 한글 형태소 분석
KoNLPy https://konlpy-ko.readthedocs.io/ko/v0.4.3/ >> from konlpy.tag import Kkma >>> from konlpy.utils import pprin" data-og-host="konlpy-ko.readthedocs.io" data-og-source-url="https://konlpy-ko.r..
truman.tistory.com
[NLP] 코랩에 konlpy 설치 후 okt 사용해보기
1. 라이브러리 설치 # bash 셸로 명령어 입력하여 라이브러리 설치하기 %%bash apt-get update apt-get install g++ openjdk-8-jdk python-dev python3-dev pip3 install JPype1 pip3 install konlpy 2. 환경설정..
pinggoopark.tistory.com
[시각화] 파이썬으로 한글 워드클라우드(Word Cloud) 생성하고 원하는 이미지 형태로 출력하기
안녕하세요. 오늘 소개해드릴 코드는 한글 문서의 단어를 추출하여 워드클라우드(Word Cloud)로 시각화하는 방법입니다. 파이썬에서 시각화는 거의 모두 matplotlib 라이브러리를 기반으로 하고 있습
doitgrow.com
[python] 네이버 블로그 크롤링 결과로 WordCloud 시각화하기
안녕하세요! 오늘은 저번에 만들었던 네이버 블로그 크롤러를 이용해서 txt 파일을 만들고 만들어진 텍스트 파일을 이용하여 워드 클라우드(WordCloud)로 시각화해보도록 하겠습니다. step1. 데이터
wonhwa.tistory.com