
언빌리버블티
[Python] Pandas 데이터 프레임 병합 메서드 - pd.merge() 본문
Pandas 데이터 프레임 합치기 - 2
pd.merge()
- 두 데이터 프레임을 각 데이터에 존재하는 고유 Key값을 기준으로 병합한다.
- DataFrame 기존 병합 메서드 join() 보다 좀 더 세부적인 설정이 가능한 메서드이다.
- index - columns 기준 병합이 가능하다.
- indicator : 병합에 대한 정보를 확인할 수 있다.
- validate : 병합 방식을 확인할 수 있다.
- SQL에서 JOIN과 같은 역할을 수행한다.
- DataFrame 기존 병합 메서드 join() 보다 좀 더 세부적인 설정이 가능한 메서드이다.
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False,
suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
각 파라미터에 대한 설명
- left : 기준 테이블
- right: left와 병합할 테이블
- how : 병합시 기준이 될 인덱스를 정하는 방법. default = inner
- left는 기존 테이블
- right는 병합할 테이블
- inner은 두 테이블의 인덱스의 교집합
- outer은 두 테이블의 인덱스의 합집합
- on : 열 기준 병합시 기준으로할 열의 이름이 서로 같다면, 기준이 되는 열을 정할 수 있다.
- left_on / right_on : 열 기준 병합 시 기준으로 할 열의 양측 이름이 다를때 어떤 열을 기준으로 할지 정한다.
- left_on : 기준열 이름이 다를 때, 왼쪽 기준열
- right_on : 기준열 이름이 다를 때, 오른쪽 기준열
- left_index / right_index : 어떤 테이블의 인덱스를 기준으로 병합을 할 지 지정한다. True or False
- sort : 병합 후 인덱스의 사전적 정렬 여부
- suffixes : 병합할 테이블 사이에 열 이름이 중복되는 경우 해당 열에 붙일 접미사를 지정
- 튜플로 두 값을 한번에 입력.
- copy : 사본을 생성할지 여부.
- indicator : True로 할경우 병합이 완료된 테이블에 추가로 열을 하나 생성하여 병합 정보를 출력.
- validate : {'1:1' / '1:m' / 'm:1' / 'm:m'} 병합 방식 검사
데이터 예시 )
s1 = pd.DataFrame({'Num':[10, 11, 12, 13, 14], 'Name':['철수', '유리', '짱구', '훈이', '맹구']})
s2 = pd.DataFrame({'Num':[10, 11, 12, ], 'Region':['대전', '서울', '부산']}) Num Name
0 10 철수
1 11 유리
2 12 짱구
3 13 훈이
4 14 맹구
Num Region
0 10 대전
1 12 서울
2 15 부산- 두 테이블은 Num이라는 변수를 공통으로 가지는 데이터프레임이다.
- 이 공통된 변수를 기준으로 데이터프레임을 merge한다.
how
: join 형식 지정
# 기준열 이름이 같을 때
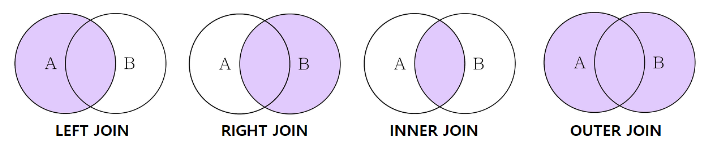
pd.merge(left, right, on = '기준열', how = '조인방식')1) Left Join : 왼쪽 테이블을 기준으로 조인
- 오른쪽 테이블에 존재하지 않는 값은 NaN으로 채운다.
left = s1
right = s2
# s1을 기준으로 joiin
pd.merge(s1, s2 , on = 'Num', how = 'left')
2) Right Join : 오른쪽 테이블을 기준으로 조인
- 왼쪽 테이블에 존재하지 않는 값은 NaN으로 채운다.
# s2 를 기준으로 join
pd.merge(s1, s2 , on = 'Num', how = 'right')
3) Inner Join : 교집합
- 양쪽 테이블에 공통적으로 가지고 있는 열만 조인
pd.merge(s1, s2 , on = 'Num', how = 'inner')
4) Outer Join : 합집합
- 두 테이블의 모든 값들을 다 가져온다.
- 왼쪽, 오른쪽 테이블 어디에도 없는 값은 NaN 으로 채운다.
pd.merge(s1, s2 , on = 'Num', how = 'outer')
on
: '기준이 되는 컬럼' 지정
공통으로 들어가는 기준 열이 여러 개일 경우
pd.merge(left, right, on = ['col1', 'col2'])공통이 되는 기준 열의 이름이 다를 때
- 양 테이블에서 기준이 되는 열의 이름이 다를 경우 왼쪽 테이블에서 기준으로 할 컬럼과 오른쪽 테이블에서 기준으로 할 컬럼을 지정해줘야 한다.
# 기준열 이름이 다를 때
pd.merge(left, right, left_on = '왼쪽 열', right_on = '오른쪽 열', how = '조인방식')
'Language > Python' 카테고리의 다른 글
| [Python] Pandas 데이터프레임 조건 탐색 및 대치 메서드 pd.where 과 np.where 차이 (0) | 2022.10.11 |
|---|---|
| [Python] Pandas Dataframe 누적합과 누적곱 구하기 - pd.cumsum() / pd.cumprod() (0) | 2022.10.11 |
| [Python] Pandas 데이터 프레임 병합 메서드 - pd.concat() (0) | 2022.10.07 |
| [Python] 수치형 변수의 구간화 - pd.cut() & pd.qcut() (0) | 2022.10.06 |
| [Python] koreanize_matplotlib : matplotlib 한국어 폰트 자동 설정 패키지 (0) | 2022.10.05 |
'Language/Python' Related Articles
more




Comments